- Прогнозирование временных рядов нейронными сетями. Keras. Часть 1.
- Обучающая выборка
- Проверочная выборка
- Прогнозирование акций Лукойл
- Что такое OHLC?
- Подготовка данных
- Проверка алгоритма подготовки данных
- Код подготовки данных для временного ряда
- Одномерная свертка
- X Международная студенческая научная конференция Студенческий научный форум — 2018
- ПРОГНОЗИРОВАНИЕ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ
- Система прогнозирования на базе нейронных сетей в промышленности
- Кратко о нейронных сетях
- Брифинг
- Обучение и проверка сетей
- Программная реализация
- Выводы
Прогнозирование временных рядов нейронными сетями. Keras. Часть 1.
Продолжу рассматривать использование библиотеки Keras в решении задач различного рода. На этот раз рассмотрю, как работает прогнозирование временных рядов.
Разбираю код Дмитрия Романова, ведущего курс по нейронным сетям в «Университете Искуственного Интеллекта». Мой notebook с моделированием. Я немного оптимизировал код Дмитрия и добавил ряд пояснений, позволяющих разобраться в теме.
С временными рядами мы сталкиваемся повседневно. Это может быть описание каких-то природных событий, например, прогноз температуры, который жестко привязан к времени. Поменять местами последовательность нельзя, временной ряд рассыплется, если прогноз на 10-е поставить на 5-е число. Это будут совершенно другие данные. Т.е. делать перемешивание, как в случае, например, с определением авторства текстов, нельзя. К таким данным условно можно отнести многие, даже не представляющие собой зависимость именно от времени. Важно, что отсчеты нельзя менять местами. Например, аудиопоток, цены на акции, даже слова, поскольку изменить порядок букв в слове нельзя без искажения слова.
Обучающая выборка
Рассмотрим простой пример. Например, есть вектор, описывающий среднюю дневную температуру в течение 100 лет. Нужно построить прогноз на день вперед. Подготовим исходные данные для обучения сети.
 Подготовка данных для анализа временных рядов на нейронных сетях
Подготовка данных для анализа временных рядов на нейронных сетях
- xTrainCount = 36500 отсчетов — длина вектора описывающего погоду за 100 лет * 365 дней.
- xLen = 100 — длина вектора xTrain.
- stepsForward = 1 — длина вектора yTrain или количество шагов (дней) на которое делается прогноз погоды.
- Shft = 1 — смещение вектора xLen относительно предыдущего. Обычно смещение делают на единицу.
- xCount = xTrainCount — xLen + 1 – stepsForward — количество строк в матрице, которое получится после «раскусывания» исходного временного ряда на xLen + stepsForward.
- Выборка xTrain — матрица с размерностью (xTrainCount — xLen + 1 – stepsForward, xLen).
- Выборка yTrain — матрица с размерностью (xTrainCount — xLen + 1 – stepsForward, stepsForward).
- Каждое значение yTrain — это значение температуры в некоторый день, но оно определяется температурой за предыдущие xLen дней. Нейронка пытается обобщить, как значение yTrain длиной stepsForward (предсказание на 1 или более дней) зависит от значений xTrain длиной xLen. Т.е. в какой-то степени yTrain = f(xTrain).
- При таком перемешивании мы как бы ставим задачу нейронной сети найти взаимосвязь последовательности длиной stepsForward (например, в случае прогноза погоды на 1 день) из значений в исходной выборке от предыдущих xLen значений (например, от 50 предыдущих дней).
- Если мы задаем поиск закономерностей между значением yTrain длиной stepsForward и остальными значениями, то в случае, когда stepsForward > 1, мы тренируем нейронную сеть на предсказание на несколько дней вперед.
- При наличии нейронной сети, предсказывающей на 1 день вперед, можно сделать предсказание на 2 и более дней, подавая на вход значение, предсказанное нейронной сетью ранее и убирая с начала по одному дню, чтобы длина вектора не изменилась. Однако, для такого варианта точность предсказания нейронкой на один день должна быть очень высокой, иначе прогноз быстро станет случайным.
Проверочная выборка
Важный вопрос, как формируется проверочная выборка. В случае с временными рядами все не так просто, как с некоторыми другими данными. В данном случае нельзя случайным образом выбрать, например, 20% данных из xTrain и yTrain.
P.S. Цифры на графике обозначают некоторую общность данных — это не данные выборок. Например, желтые — это вектора относящиеся к xTrain.

- Проверочная выборка берется из векторов xTrain и yTrain.
- Для проверочной выборки берется «хвост» данных длиной valLen.
- Данные для проверочной выборки берутся снизу (с конца), чтобы быть максимально близкими к прогнозным значениям. Скажем, в случае прогноза погоды если взять начало последовательности, то это будут данные столетней давности. За 100 лет ситуация с погодой могла измениться, поэтому использовать их для проверки неправильно.
- Между проверочной выборкой и обучающей нужно сделать промежуток длиной xLen + stepsForward. В этом промежутке данные xTrain и xVal в значительной степени пересекаются. Нейронка может «заучить» на обучающей выборке общие с проверочной выборкой паттерны. Это может обманчиво улучшить показатели на проверочной выборке. Поэтому приходится пожертвовать данными из этого промежутка — они исключаются из выборок.
- При коротких выборках, когда данных мало, можно исключать не диапазон xLen + stepsForward , а меньше, например, 80% от этой длины или менее. Это уже в значительной степени уменьшает взаимное перемешивание.
Прогнозирование акций Лукойл
В предыдущей статье по нейронным сетям я уже рассмотрел загрузку данных с ftp/http. В данном случае URL для загрузки данных:
Загрузим данные из .csv с помощью Pandas. Нужно обратить внимание, что в качестве разделителя в csv используется «;» и в явном виде передать sep=’;’.
Что такое OHLC?
Видно, что показатели OHLC берутся с интервалом в 1 минуту.
OHLC – это сокращенное обозначение котировок, которые указываются для элементарной диаграммы ценового графика. В этой аббревиатуре :
- О обозначает Open – цену открытия интервала.
- H означает High (в нашем случае Max) — максимум цены интервала.
- L означает Low (Min) – минимум цены интервала.
- C означает Close – цену закрытия интервала.
- Volume — объем операций.
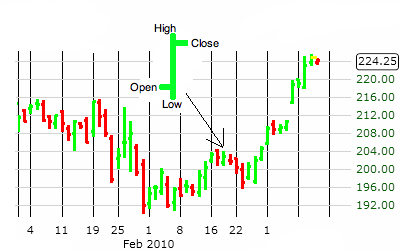 График OHLC
График OHLC
На графике OHLC каждый интервал времени (например, 5 минут) представлен OHLC ценами внутри этого интервала. OHLC — это один из основных показателей фьючерсной торговли на FOREX.
Подготовка данных
Для построения прогноза в данном случае не нужны колонки со временем и датой. Главное чтобы отсчеты брались через равные промежутки времени.
Файлы с данными по акциям идут по годам. Объединим два года для анализа.
Выведем данные OHLC на график:
Значения OHLC достаточно близки друг к другу, поэтому слились на первом графике.
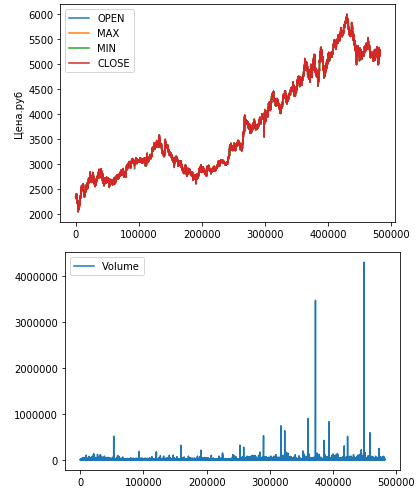
На втором графике видны два аномально высоких значения операций.
Проверка алгоритма подготовки данных
Смоделируем работу алгоритма по «раскусыванию» временного ряда на составляющие. Сгененирую простую последовательность, чтобы удобно ориентироваться в работе кода:
Исходную последователность преобразуем в массив «раскусыванием»:
Для получения yTrain нужно в каждой строке брать вектор длиной stepsForward, начиная с xLen, поскольку последовательность до xLen пошла в xTrain. Соотвественно, range начнется с xLen.
Видно, что значения вектора yTrain начинаются с xLen. Каждый элемент длиной stepsForward = 1. По сути, нейронка ищет закономерность между каждым yTrain и предыдущими xLen значений xTrain.
После получения исходной последовательности нужно разрезать массив на две части: обучающую выборку и валидационную. Кроме того между ними нужно выбросить «прослойку» размером bias записей. Это важно, чтобы гарантированно исключить перемешивание, т.е. чтобы в валидационную выборку не попали значения из обучающей.
В следюущей статье я сделал другой вариант разбивки на обучающую и проверочную выборку, он компактнее и понятнее.
После запуска «раскусывалки» получим следующее:
- 3 записи остались для для проверочной выборки.
- 8 записей были выброшены (bias)
- 4 записи с начала оставлись для обучающей выборки
итого 15 записей.
Код подготовки данных для временного ряда
Одномерная свертка
Забегая вперед скажу, что на этом временном ряде наилучшие показатели обеспечила одномерная свертка.
Источник
X Международная студенческая научная конференция Студенческий научный форум — 2018








ПРОГНОЗИРОВАНИЕ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ
Второй важный этап при построении нейросетевой прогнозирующей системы — это определение следующих трех параметров: периода прогнозирования, горизонта прогнозирования и интервала прогнозирования. Период прогнозирования — это основная единица времени, на которую делается прогноз. Горизонт прогнозирования — это число периодов в будущем, которые покрывает прогноз. То есть, может понадобиться прогноз на 10 дней вперед, с данными на каждый день. В этом случае период — сутки, а горизонт — 10 суток. Наконец, интервал прогнозирования — частота, с которой делается новый прогноз. Часто интервал прогнозирования совпадает с периодом прогнозирования. Выбор периода и горизонта прогнозирования обычно диктуется условиями принятия решений в области, для которой производится прогноз. Выбор этих двух параметров — едва не самое трудное в нейросетевом прогнозировании. Для того чтобы прогнозирование имело смысл, горизонт прогнозирования должен быть не меньше, чем время, необходимое для реализации решения, принятого на основе прогноза. Таким образом, прогнозирование очень сильно зависит от природы принимаемого решения. В некоторых случаях, время, требуемое на реализацию решения, не определено, например, как в случае поставки запасных частей для пополнения запасов ремонтных предприятий. Существуют методы работы в условиях подобной неопределенности, но они повышают вариацию ошибки прогнозирования. Поскольку с увеличением горизонта прогнозирования точность прогноза, обычно, снижается, часто можно улучшить процесс принятия решения, уменьшив время, необходимое на реализацию решения и, следовательно, уменьшив горизонт и ошибку прогнозирования.
В некоторых случаях не так важно предсказание конкретных значений прогнозируемой переменной, как предсказание значительных изменений в ее поведении. Такая задача возникает, например, при предсказании момента, когда текущее направление движения рынка (тренд) изменит свое направление на противоположное.
Точность прогноза, требуемая для конкретной проблемы, оказывает огромное влияние на прогнозирующую систему. Также огромное влияние на прогноз оказывает обучающая выборка.
Первое, с чем сталкивается пользователь любого нейропакета — это необходимость подготовки данных для нейросети. На практике именно предобработка данных может стать наиболее трудоемким элементом нейросетевого анализа. Причем, знание основных принципов и приемов предобработки данных не менее, а может быть даже более важно, чем знание собственно нейросетевых алгоритмов. Последние, как правило, уже «зашиты» в различных нейроэмуляторах, доступных на рынке. Сам же процесс решения прикладных задач, в том числе и подготовка данных, целиком ложится на плечи пользователя.
Общий алгоритм прогнозирования с помощью нейронной сети состоит из следующих пунктов:
получение временного ряда с интервалом в выбранную временную итерацию;
заполнение «пробелов» в истории;
сглаживание ряда методом скользящих средних (или другим);
получение ряда относительного изменения прогнозируемой величины;
формирование таблицы «окон» с глубиной погружения временных интервалов;
добавление к таблице дополнительных данных (например, изменение величины за предыдущие годы);
определение обучающей и валидационной выборок;
подбор параметров нейросети;
проверка работоспособности нейросети в реальных условиях.
Характерный пример успешного применения нейронных вычислений в финансовой сфере — управление кредитными рисками. Как известно, до выдачи кредита банки проводят сложные статистические расчеты по финансовой надежности заемщика, чтобы оценить вероятность собственных убытков от несвоевременного возврата финансовых средств. Такие расчеты обычно базируются на оценке кредитной истории, динамике развития компании, стабильности ее основных финансовых показателей и многих других факторов. Один широко известный банк США опробовал метод нейронных вычислений и пришел к выводу, что та же задача по уже проделанным расчетам подобного рода решается быстрее и точнее. Например, в одном из случаев оценки 100 тыс. банковских счетов новая система, построенная на базе нейронных вычислений, определила свыше 90% потенциальных неплательщиков.
Другая очень важная область применения нейронных вычислений в финансовой сфере — предсказание ситуации на фондовом рынке. Стандартный подход к этой задаче базируется на жестко фиксированном наборе «правил игры», которые со временем теряют свою эффективность из-за изменения условий торгов на фондовой бирже. Кроме того, системы, построенные на основе такого подхода, оказываются слишком медленными для ситуаций, требующих мгновенного принятия решений. Именно поэтому основные японские компании, оперирующие на рынке ценных бумаг, решили применить метод нейронных вычислений. В типичную систему на базе нейронной сети ввели информацию общим объемом в 33 года деловой активности нескольких организаций, включая оборот, предыдущую стоимость акций, уровни дохода и т.д. Самообучаясь на реальных примерах, система нейронной сети показала большую точность предсказания и лучшее быстродействие: по сравнению со статистическим подходом дала улучшение результативности в целом на 19%.
К недостаткам прогнозирования с помощью нейронных сетей можно отнести следующее: длительное время обучения, проблема переобучения, трудность определения положения обучающей выборки и значащих входов.
Источник
Система прогнозирования на базе нейронных сетей в промышленности
Кратко о нейронных сетях
Нейронная сеть представляют собой систему соединённых и взаимодействующих между собой простых процессоров (нейронов).
Рисунок 1. Структурная схема нейронной сети (зеленый цвет – входной слой нейронов, синий – скрытый(промежуточный) слой нейронов, желтый – выходной слой нейронов). 
Нейрон – базовый элемент нейронной сети, единичный простой вычислительный процессор способный воспринимать, преобразовывать и распространять сигналы, в свою очередь объединение большого количества нейронов в одну сеть позволяет решать достаточно сложные задачи.
Рисунок 2. Схема нейрона. 
Нейросетевой подход свободен от модельных ограничений, он одинаково годится для линейных и сложных нелинейных задач, а также задач классификации. Обучение нейронной сети в первую очередь заключается в изменении «силы» связей между нейронами. Нейронные сети масштабируемы, они способны решать задачи как в рамках единичного оборудования, так и в масштабах заводов в-целом.
Брифинг
Цель — прогнозирование содержания серы в продукте с максимально возможной точностью, что в свою очередь позволит держать основные технологические параметры в оптимальных значениях как для качества продукта, так и с точки зрения оптимизации процесса.
Единицы измерения — ppm (одна миллионная доля).
Входные данные — исторические значения технологических параметров объекта.
Данные для проверки прогноза сети — ежесуточные лабораторные анализы содержания серы.
Обучение и проверка сетей
Всего было использовано 531 наблюдение, общая выборка была поделена следующим образом: 70% наблюдений выборки использовалось для обучения сети, 30% использовалось в качестве контрольной выборки для оценки качества обучения сети и дальнейшего сравнения сетей между собой. Среднее содержание серы во всех наблюдениях составило 316,7ppm.
Всего по результатам обучения было отобрано 4 сети, сети имеют следующую конфигурацию:
Сеть №1: 20-22-1
Сеть №2: 20-26-1
Сеть №3: 20-27-1
Сеть №4: 20-16-1
Конфигурация сетей представлена в виде AA-BB-C, где AA – количество нейронов во входном слое, BB – количество нейронов в скрытом слое, C – количество нейронов в выходном слое.
Обучение сетей производилось в специализированных пакетах, на данный момент их великое множество (SPSS, Statistica и пр), ниже приведены гистограммы распределения ошибок обученных сетей на всем множестве наблюдений:
Рисунок 3. Гистограмма распределения ошибки для сети №1. 
Рисунок 4. Гистограмма распределения ошибки для сети №2. 
Рисунок 5. Гистограмма распределения ошибки для сети №3. 
Рисунок 6. Гистограмма распределения ошибки для сети №4. 
По полученным гистограммам можно сделать вывод, что ошибка сети подчиняется нормальному закону распределения, т.е. можно разделить размер ошибки на 3 области (для упрощения распределение считается нормализованным): 
±σ1 (область 1 сигма — величина ошибки в 68% процентах прогнозов находится в данном диапазоне);
±σ2 (область 2 сигма — величина ошибки в 95% процентах прогнозов находится в данном диапазоне);
±σ3 (область 3 сигма — грубые ошибки, промахи, менее чем в 5% процентах случаев, величина ошибки больше, чем в области ±σ2).
Ошибки по областям распределения:
№ сети и ±σ1 (68% прогнозов)
Сеть №1: ±16,4ppm
Сеть №2: ±18,3ppm
Сеть №3: ±19ppm
Сеть №4: ±18,6ppm
№ сети и ±σ2 (95% прогнозов)
Сеть №1: ±43,9ppm
Сеть №2: ±47,6ppm
Сеть №3: ±42,8ppm
Сеть №4: ±41ppm
Причина грубых ошибок (промахов) в области ±σ3 – это работа сети с данными сильно отличающимися от тех, которые присутствовали в обучающей выборке.
Также важным показателем качества обучения нейронной сети является величина средней абсолютной ошибки.
Размер средней абсолютной ошибки:
Сеть №1 — 14,4ppm
Сеть №2 — 13,4ppm
Сеть №3 — 14,3ppm
Сеть №4 — 13,6ppm
Ниже представлены графики зависимости содержания серы в продукте (лабораторный анализ) и величины абсолютной ошибки:
Рисунок 7. График зависимости содержания серы и абсолютной ошибки для сети №1. 
Рисунок 8. График зависимости содержания серы и абсолютной ошибки для сети №2. 
Рисунок 9. График зависимости содержания серы и абсолютной ошибки для сети №3. 
Рисунок 10. График зависимости содержания серы и абсолютной ошибки для сети №4. 
Программная реализация
Для просмотра прогнозов в реальном времени использовалась собственная разработка на C#, данные получались от OPC-сервера, изначально было разработано приложение с минимальным набором возможностей (графики, XML-импорт, экспорт графика, добавление произвольного параметра на график), в дальнейшем планируется добавить сохранение истории в БД, сравнение прогнозов сети с реальными историческими значениями по заданным временным отметкам, обучение сетей уже в своем пакете, сравнение сетей между собой и не только.
Рисунок 11. Скриншот первой версии 
Выводы
Благоприятные условия работы для сети:
Наименьшую ошибку сеть выдает при содержании серы в конечном продукте в диапазоне 240-250ppm ÷ 400-410ppm (содержание серы, полученное в результате лабораторного анализа, а не прогноза сети), это связано с тем, что большинство измерений было произведено именно в данном диапазоне, и, собственно, на них и была обучена сеть. Нейронные сети имеют способность к обобщению информации, т.е. способны давать прогноз, в том числе основываясь на данных с которыми сеть не работала до данного момента, используя закономерности обучающей выборки, но в данном случае не смотря на такую особенность сети следует помнить, что конечный результат будет малопредсказуем, но с уверенностью можно утверждать что ошибка возрастет.
В случае серьезных изменений на объекте сеть необходимо переобучить.
Источник

