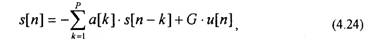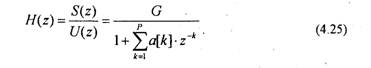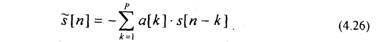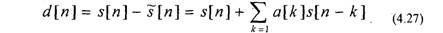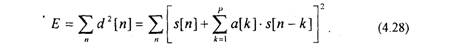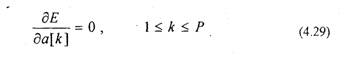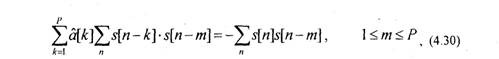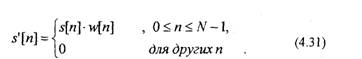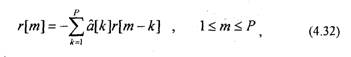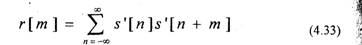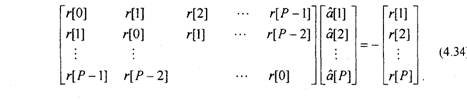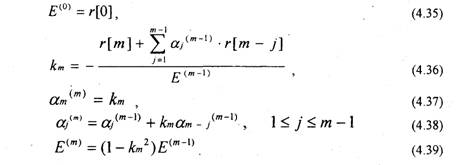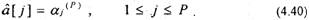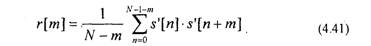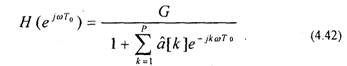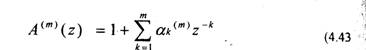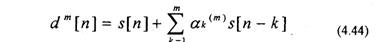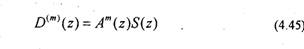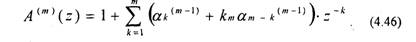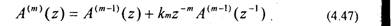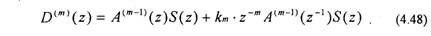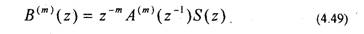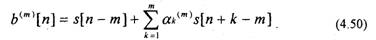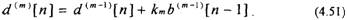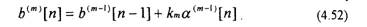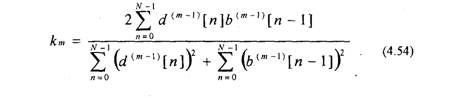Суть линейного предсказания в нахождении коэффициентов ak (k=1..p) для формулы:
p
x[n] =
∑
(ak x[n-k])
(1)
k=1
и последующем использовании этой формулы. Другими словами мы должны построить линейный многочлен, позволяющий с хорошей точностью вычислять значение любого отсчета в сигнале по значениям предыдущих p отсчетов. Коэффициенты ak и называются коэффициентами линейного предсказания.
Фактически, имея некоторый сигнал, мы имеем статистическую выборку которую можно представить в виде таблицы:
х[n-p]
х[n-p+1]
х[n-p+2]
. . .
х[n-1]
х[n]
х[0]
х[1]
х[2]
. . .
x[p-1]
x[p]
х[1]
х[2]
х[3]
. . .
x[p]
x[p+1]
х[2]
х[3]
х[4]
. . .
x[p+1]
x[p+2]
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
. . .
х[N-p-1]
х[N-p]
х[N-p+1]
. . .
x[N-2]
x[N-1]
То есть нахождение коэффициентов линейного предсказания сводится к вычислению коэффициентов линейной регрессии для данной статистической выборки и мы можем пользоваться методами математической статистики.
Минимизируем сумму квадратов ошибок для каждого из вычисляемых отсчетов. Ошибка для отсчета x[n] равна
p
δ[n] = x[n] —
∑
(ak x[n-k])
(2)
k=1
А минимизируемая функция равна
N-1
N-1
p
N-1
N-1
p
E =
∑
δ 2 [n] =
∑
x[n] —
∑
(ak x[n-k])) 2 =
∑
x 2 [n] — 2
∑
x[n]
∑
(ak x[n-k]) )+
n=0
n=0
k=1
n=0
n=0
k=1
N-1
p
N-1
p
N-1
+
∑
(
∑
(ak x[n-k])) 2 =
∑
x 2 [n] — 2
∑
(ak
∑
(x[n] x[n-k])) +
n=0
k=1
n=0
k=1
n=0
p
p
N-1
+
∑
∑
ak aj
∑
(x[n-k]x[n-j]))
(3)
j-1
k=1
n=0
Продифференцируем E по ak и приравняем частные производные нулю для нахождения экстремума:
N-1
p
N-1
dE/dak =
∑
(x[n] x[n-k])) +
∑
aj
∑
(x[n-k]x[n-j]))=0
(4)
n=0
j=1
n=0
Заменив для удобства восприятия j на i, а k на j получим систему p линейных уравнений c p неизвестными :
p
∑
aicij=c0j
(5.1)
i=1
N-1
cij=cji=
∑
x[n-i]x[n-j])
(5.2)
n=0
Эта система называется системой уравнений Юла-Уокера. Погрешность найденных коэффициентов оценивается как:
p
p
p
p
E = c00-2
∑
aic0i+
∑
ai
∑
ajcij = c00 —
∑
aic0i
(6)
i=1
i=1
j=1
i=1
Есть два основных подхода для решения системы уравнений Юла-Уокера.
Источник
Анализ речи на основе линейного предсказания
Анализ речи на основе линейного предсказания базируется на использовании модели речевого сигнала, представленной на рис.4.1, Основная задача метода состоит в том, чтобы по наблюдениям последовательности отсчетов речевого сигнала s[n] определить коэффициенты a[k] цифрового фильтра указанной модели [14,15,17].
Найденные значения коэффициентов, которые называют коэффициентами линейного предиктивного кодирования (ЛПК), могут применяться при определении частоты основного тона, при кодировании речи в соответствии с АДИКМ, в задачах распознавания и синтеза речи.
Главное допущение метода линейного предсказания состоит в том, что речевой отсчет на выходе голосового тракта s[n] может быть предсказан по линейной комбинации своих предыдущих значений и значению сигнала и [п]
где G — коэффициент усиления; Р — порядок линейного предсказателя. Е этом случае передаточная функция предсказателя соответствует передаточной функции рекурсивного фильтра
Определение коэффициентов линейного предсказания речи имеет прямое отношение к спектральному анализу, основанному на использовании АР-модели. Вместе с тем, использование модели, приведенной на рис.4.1, вносит некоторую специфику. Поэтому рассмотрим оценивание ЛПК речи подробнее. Так как отсчеты возбуждающей последовательности и[п] неизвестны, то последовательность s[n] может быть предсказана только по своим предыдущим значениям
Ошибка предсказания в этом случае будет равна
Определим коэффициенты a[k] таким образом, чтобы сумма квадратов ошибок предсказания была минимальна
Для минимизации (4.28) найдем частные производные (4.28) по a[k] и приравняем их к нулю
В результате получим систему уравнений
где a[k] -оценки коэффициентов a[k].
В общем случае суммирование в (4.30) должно выполняться по всем значениям п. Однако на практике суммирование по я в уравнении (4.30) выполняют для ограниченного числа отсчетов s[n], чтобы соблюдалось условие стационарности s[n]. Для этого ограничивают последовательность s[n] с помощью окна w[n]
Тогда систему уравнений (4.30) можно переписать в виде
автокорреляционная функция ограниченной последовательности s'[n].
Так как автокорреляционная функция является четной, т.е. г[от]=г[-/п],
то (4.32) можно записать в матричной форме ;
Матричное уравнение (4.34) имеет структуру аналогичную уравнению (2.35) и может быть решено с помощью рекурсивного алгоритма Левинсона — Дарбина. В соответствии с этим алгоритмом решение для предсказателя т-го порядка получается на основе решения для предсказателя т-\ порядка. Формально алгоритм определяется следующими соотношениями 4,14,15,171:
Уравнения (4.35 — 4.39) решаются рекурсивно для т=1, 2, . Р: Отметим, что для от=1 параметр а^ = k\ = r[l]/r[0] и. Е^ = (1 — k^)r[0]. Для конечного решения порядка Р коэффициенты линейного предсказания будут равны
Коэффициенты km называются коэффициентами отражения. Е представляет сумму квадратов ошибки предсказания для предсказателя т-го порядка. Автокорреляционную функцию последовательности s'[n] оценивают на основе соотношения:
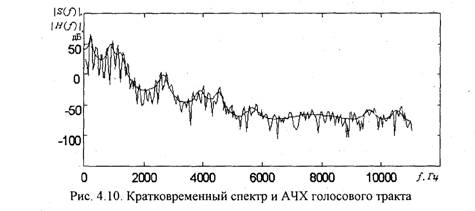
Линейное предсказание речи можно использовать для определения частотной характеристики голосового тракта
Данная характеристика соответствует медленно меняющейся составляющей кратковременного спектра речевого сигнала. На рис. 4.10 представлен кратковременный спектр речевого сигнала и АЧХ голосового тракта, вычисленная с помощью (4.42). Порядок фильтра Р=28. На графике АЧХ хорошо представлены форманты.
Недостатком рассмотренного метода определения ЛПК является необходимость вычисления матрицы автокорреляций. Кроме этого, если вычисленные значения ЛПК применяются при синтезе речи в соответствии со схемой, показанной на рис.4.1, то возникают вопросы обеспечения устойчивости цифрового рекурсивного фильтра высокого порядка.
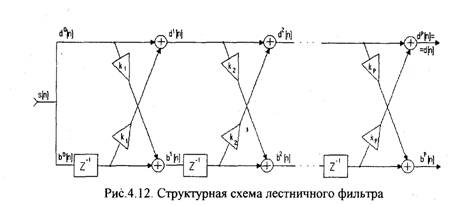
В настоящее время развит класс методов, которые оценивают ЛПК непосредственно по отсчетам последовательности s[n] и которые лучше приспособлены для решения задач синтеза речи. Эти методы базируются на использовании лестничного фильтра [17].
Эта передаточная функция соответствует инверсному фильтру и являете» ‘^j обратной по отношению к передаточной функции предсказателя (4.25). Е ‘ соответствии с (4.27) на вход инверсного фильтра поступает речевой сигнал s[n], а на выходе формируется ошибка предсказания. Ошибка предсказания;
для предсказателя т-го порядка будет равна
Найдем z-преобразование (4.44). Тогда
Подставив (4.38) в (4.43), получим
Отсюда получаем рекурсивное выражение для вычисления A»»‘\z)
Подставляя (4.47) в (4.45), получаем выражение для ошибки предсказания
Первый член в (4.48) соответствует ошибке предсказания для предсказателя (т-1 )-го порядка. Для второго члена в (4.48) без km введем обозначение
Выражению (4.49) соответствует разностное уравнение
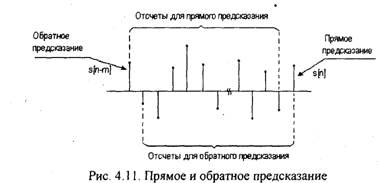
Данное уравнение соответствует обратному предсказанию, т.е. оно позволяет предсказать отсчет по предстоящим отсчетам s[(n-m)+k] и (рис.4.11).
Сравнивая (4.50) и (4.44), отмечаем, что b»‘[n] соответствует ошибке обратного предсказания. Таким образом, ошибка прямого предсказания (4.48) может быть представлена в виде
Выполнив аналогичные преобразования для (4.50), получим симметричное выражение для ошибки обратного предсказания
Уравнения (4.51) и (4.52) являются рекуррентными и определяют ошибки предсказаний для предсказателя т-го порядка через ошибки предсказания для предсказателя (m-l)-ro порядка. При этом для предсказателя нулевого порядка
Уравнения (4.51) и (4.52) соответствуют лестничному фильтру и могут быть представлены в виде структурной схемы, изображенной на рис.4.12.
Коэффициенты отражения km могут вычисляться в соответствии с уравнениями (4.35 — 4.39). Однако имеется и иная возможность. В [11,36] показано, что коэффициенты отражений можно вычислять через ошибки предсказания d»[n\ и &»*[«] в соответствии с соотношением
Выражение (4.54) является нормированной корреляционной зависимостью и показывает степень корреляции между ошибкой прямого предсказания и ошибкой обратного предсказания. Поэтому коэффициенты km иногда называют коэффициентами частной корреляции. Уравнение (4.54) может использоваться вместо уравнения (4.36) при оценивании коэффициентов линейного предсказания.
Оценки коэффициентов km лестничного фильтра, вычисленные с помощью (4.54), будут находиться в диапазоне —1 r и Г — задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания (/л-М, то в соответствии с (4.55) ошибка долговременного предсказания d ;[п] будет равна
Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности s[n> ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рис. 4.14) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой (см. §4.8). Фильтр W(z) , учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рис.4.14, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
Существует несколько различных способов формирования функции возбуждения: многоимпульсное, регулярно-импульсное и векторное (кодовое) возбуждение [36]. Соответствующие алгоритмы представляют многоимпульсное (MLPC), регулярно-импульсное (RPE-LPC) и линейное предсказание с кодовым возбуждением (code excited linear prediction — CELP). MLPC использует функцию возбуждения, состоящую из множества нерегулярных импульсов, положение и амплитуда которых выбирается так, чтобы минимизировать ошибку восстановления. Алгоритм RPE-LPC является разновидностью MLPC, когда импульсы имеют регулярную расстановку. В этом случае оптимизируется амплитуда и относительное положение всей последовательности импульсов в пределах сегмента речи. CELP представляет способ, который основывается на векторном квантовании. В соответствии с этим способом из кодовой книги возбуждающих последовательностей выбирается квазислучайный вектор, который минимизирует квадрат ошибки восстановления. Кодовая книга используется как на этапе сжатия речевого сигнала, так и на этапе его восстановления. Для восстановления сегмента речевого сигнала необходимо знать номер соответствующего вектора воз-бужденияг в кодовой книге, параметры фильтров Ai,(z) и A(z), коэффициент усиления. Восстановление речевого сигнала по указанным параметрам выполняется в декодере только с помощью элементов, входящих в верхнюю часть схемы, изображенной на рис.4.14.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
2) CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефонной связи;
3) VCELP со скоростью передачи 7,95 Кбит/с (vector sum excited linear prediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
4) LD-CELP (low-delay CELP) одобрен стандартом МККТТ G.728. В данном стандарте достигается небольшая задержка примерно 0,625 мс (обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией Ai,(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP),