- ПРИМЕНЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ ФИНАНСОВЫХ ВРЕМЕННЫХ РЯДОВ
- Введение.
- Формирование входов нейронной сети
- Обучение нейронной сети
- Выбор функции ошибки
- Использование комитета нейросетей
- Заключение
- Создаем нейронную сеть для прогнозирования временного ряда
- Интерес к нейронным сетям
- Первая нейронная сеть
- Прогнозирование с помощью нейронной сети
- Шаг 1. Инициализация и исходные данные
- Шаг 2. Предварительная обработка исходных данных
- Шаг 3. Настройка нейронной сети
- Шаг 4. Обучение сети
- Шаг 5. Тестовое прогнозирование
- Шаг 6. Оценка ошибки прогнозирования
- Результаты
- Похожие публикации
- Комментарии
ПРИМЕНЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ ФИНАНСОВЫХ ВРЕМЕННЫХ РЯДОВ
Авторы: Е.А. Ефремова, Е.В. Дунаев
Описание: В статье рассмотрены некоторые аспекты и особенности использования нейронных сетей для прогнозирования финансовых временных рядов с целью получения прибыли.
Введение.
Предсказание финансовых временных рядов – необходимый элемент любой инвестици- онной деятельности. Сама идея инвестиций – вложения денег сейчас с целью получения дохо- да в будущем – основывается на идее прогнозирования будущего. Любая задача, связанная с манипулированием финансовыми инструментами, будь то валюта или ценные бумаги, сопря- жена с риском и требует тщательного расчета и прогнозирования
Поведение рыночного сообщества имеет много аналогий с поведением толпы, характе- ризующимся особыми законами массовой психологии. Частичная предсказуемость рынка обу- словлена относительно примитивным поведением игроков, которые образуют единую хаотиче- скую динамическую систему с небольшим числом внутренних степеней свободы.
Для успешной торговли на фондовом рынке необходимо выработать систему игры, ап- робированную на прошлом поведении временного ряда, и четко следовать этой системе, не поддаваясь влиянию эмоций.
Как известно, существуют два основных подхода к анализу рынка: технический и фунда- ментальный. Первый из них базируется на теории Доу, в основе которой лежит аксиома: «Цены учитывают все», и соответственно технический аналитик использует только цены актива и раз- личные индикаторы (функции цен). Фундаментальный анализ, наоборот, ищет взаимосвязь цен актива, внешних событий и данных типа макроэкономических показателей и финансовой отчет- ности корпораций и т.д.
Применение нейронных сетей в качестве дополнения дает уникальную возможность объ- единить эти два метода. Такой анализ, в отличие от технического, не имеет никаких ограниче- ний по характеру входной информации. Это могут быть как индикаторы данного временного ряда, так и сведения о поведении других рыночных инструментов, и внешние события. Нейро- сети активно используют на Западе институциональные инвесторы (например пенсионные фонды и страховые компании), работающие с большими портфелями, для которых особенно важны корреляции между различными рынками [1].
В отличие от технического анализа, основанного на общих рекомендациях и опыте трей- дера, нейросети способны строить оптимальную модель прогнозирования, более того, модель адаптивна и меняется вместе с рынком, что особенно важно для современных высокодинамич- ных финансовых рынков, в частности российского.
Применение нейронных сетей в финансах базируется на одном фундаментальном допу- щении – замене прогнозирования распознаванием. Нейросеть не предсказывает будущее, она «старается узнать» в текущем состоянии рынка ранее встречавшуюся ситуацию и максимально точно воспроизвести реакцию рынка.
Для прогнозирования финансовых временных рядов возможно использование много- слойных персептронов. Использование сетей с обратными связями в данном случае нецелесообразно в связи с трудностью обучения таких сетей и неактуальностью основной характеристики сетей с обратными связями – краткосрочной памяти.
Необходимо определить, какие входы подавать сети и какие данные получать на выходе. В общем случае входы сети отражают динамику торгов (цены и объемы) по исследуемому ин- струменту за некоторый предыдущий период времени. Выходом сети обычно выбирается изме- нение цены исследуемого финансового инструмента в будущем. Такой выход позволяет игроку принимать решения о совершении сделок на рынке.
Формирование входов нейронной сети
Несмотря на то что предсказания являются экстраполяцией данных, нейросети на самом деле решают задачу интерполяции, что существенно повышает надежность решения. Предска- зание временного ряда сводится к типовой задаче нейроанализа – аппроксимации функций многих переменных по заданному набору примеров с помощью процедуры погружения ряда в многомерное пространство.
Для динамических систем доказана следующая теорема Такенса. Если временной ряд порождается динамической системой, то есть значения t ? есть произвольные функции со- стояния системы, то существует такая глубина погружения d (примерно равная эффективному числу степеней свободы данной динамической системы), которая обеспечивает однозначное предсказание следующего значения временного ряда. Таким образом, выбрав достаточно большое d , можно гарантировать однозначную зависимость будущего значения ряда от его d предыдущих значений:

Хотя предсказание финансовых рядов сводится к задаче аппроксимации многомерной функции, оно имеет свои особенности как при формировании входов, так и при выборе выходов нейросети. Достаточно важным также является вопрос оценки качества финансовых предска- заний для выбора и построения наилучшей стратегии обучения нейросети.
В качестве входов и выходов нейросети не следует выбирать сами значения котировок (обозначим их t C ). Действительно значимыми для предсказаний являются изменения котиро- вок. Так как эти изменения обычно гораздо меньше по амплитуде, чем сами котировки, между последовательными значениями курсов имеется большая корреляция – наиболее вероятное значение курса в следующий момент равно его предыдущему значению:

Для повышения качества обучения следует стремиться к статистической независимости входов, то есть к отсутствию подобных корреляций. Поэтому в качестве входных переменных логично выбирать наиболее статистически независимые величины, например изменения коти- ровок t ?C или логарифм относительного приращения:

Использование логарифма относительного приращения является удачным для длитель- ных временных рядов, когда уже заметно влияние инфляции. В этом случае простые разности в разных частях ряда будут иметь различную амплитуду, так как фактически измеряются в раз- личных единицах. Напротив, отношения последовательных котировок не зависят от единиц измерения и будут одного масштаба несмотря на инфляционное изменение единиц измерения. В итоге большая стационарность ряда позволит использовать для обучения большую историю и обеспечит лучшее обучение.
Отрицательной чертой погружения в лаговое пространство является ограниченный «кру- гозор» сети, тогда как технический анализ не фиксирует окно в прошлом и использует доста- точно далекие значения ряда. Например, утверждается, что максимальные и минимальные значения ряда даже в относительно далеком прошлом оказывают достаточно сильное воздействие на психологию игроков и, следовательно, должны быть значимыми для предсказаний. Недостаточно широкое окно погружения в лаговое пространство не способно предоставить такую информацию, что, естественно, снижает эффективность предсказания. С другой стороны, расширение окна до таких значений, когда захватываются далекие экстремальные значения ряда, повышает размерность сети, что в свою очередь приводит к понижению точности нейросетевого предсказания уже из-за разрастания размера сети [2].
Альтернативный способ кодирования прошлого поведения ряда позволяет решить эту проблему. Интуитивно понятно, что чем дальше в прошлое уходит история ряда, тем меньше деталей его поведения влияет на результат предсказаний. Это обосновано психологией субъ- ективного восприятия прошлого участниками торгов, которые собственно и формируют буду- щее. Следовательно, представление динамики ряда должно иметь избирательную точность – чем дальше в прошлое, тем меньше деталей – при сохранении общего вида кривой
Одним из альтернативных способов кодирования временного ряда является использо- вание в качестве входных данных значений индикаторов технического анализа на относительно далеком периоде времени и значений колебаний курса в текущем периоде.
Также достаточно перспективным инструментом здесь может оказаться вейвлетное раз- ложение (wavelet decomposition). Оно эквивалентно по информативности лаговому погружению, но легче допускает такое сжатие информации, которое описывает прошлое с избирательной точностью.
Обучение нейронной сети
При обучении нейросетей, предназначенных для прогнозирования финансовых времен- ных рядов, используют стандартный подход. Имеющиеся примеры разбивают на три выборки: обучающую, валидационную и тестовую. Обучающая выборка предназначена для подстройки синаптических коэффициентов обучаемых нейронных сетей с целью минимизации ошибки на выходе сети. Валидационная выборка используется для выбора наилучших из нескольких обу- ченных сетей и/или для определения момента останова обучения. Тестовая выборка, которая не использовалась в процессе обучения, служит для контроля качества прогнозирования
Выбор функции ошибки
Для обучения нейросети недостаточно сформировать обучающие наборы входов- выходов. Необходимо также определить ошибку предсказаний сети. Среднеквадратичная ошибка не имеет большого «финансового смысла» для рыночных рядов. Например, для выбо- ра рыночной позиции надежное определение знака курса боле важно, чем понижение средне- квадратичного отклонения. Хотя эти показатели и связаны между собой, сети, оптимизирован- ные по одному из них, будут давать худшие предсказания другого.
Ошибка сети представляется в виде функции от синаптических коэффициентов и мини- мизируется одним из градиентных методов. Традиционно используют среднеквадратичную ошибку (суммирование производится по всем выходам):

Целью прогнозирования финансовых рядов является получение и максимизация прибы- ли. Поэтому в прогнозировании финансовых рядов важна не близость прогноза к истинному значению (что обеспечивает минимизация функции среднеквадратичной ошибки), а одинаковая направленность прогноза и истинного значения. Таким свойством обладает функция

Использование комитета нейросетей
Использование различных архитектур сетей, случайность выбора первоначальных синап- тических коэффициентов, а также использование других отличающих сети параметров – все это приводит к тому, что предсказания различных нейронных сетей, обученных на одних и тех же примерах, разнятся, иногда достаточно сильно. Явно «неудачные» варианты сетей отпада- ют на этапе валидации и тестирования. А более или менее «удачные» сети можно использо- вать совместно, организовав так называемый комитет сетей, используя для принятия реше- ния значения выходов всех входящих в комитет сетей [2].
Легко показать, что среднее значение выходов комитета должно давать лучшие предска- зания, чем средняя сеть из этого комитета. Это следует из неравенства Коши

Таким образом, предпочтительно использовать для принятия решения среднее значение выходов комитета нейросетей. Более того, можно использовать не среднее значение выходов, а среднее взвешенное. Веса выбираются адаптивно, максимизируя эффективность предсказа- ний комитета на обучающей выборке. В итоге лучшие сети будут вносить наибольший вклад, в то время как предсказания сетей, дающих худшие результаты, будут вносить меньший вклад и не будут портить предсказания.
Заключение
Использование нейронных сетей для анализа финансовой информации является пер- спективной альтернативой (или дополнением) для традиционных методов исследования. В си- лу своей адаптивности одни и те же нейронные сети могут использоваться для анализа не- скольких инструментов и рынков, в то время как найденные игроком для конкретного инстру- мента закономерности с помощью методов технического анализа могут работать хуже или не работать вообще для других инструментов.
Специфика объекта исследования накладывает некоторые особенности на использова- ние нейронных сетей для анализа данных. Такой особенностью является выбор функции ошиб- ки нейронной сети, отличной от традиционной среднеквадратичной. Следует отметить, что од- ной из важных составляющих анализа данных с помощью нейронных сетей является предоб- работка данных, направленная на сокращение размерности входов сети, повышение совме- стной энтропии входных переменных и нормировку входных и выходных данных.
Дальнейшая работа (авторов) в этой области будет направлена на эмпирические иссле- дования, такие как практическая реализация нейронных сетей и построение торговых систем на базе нейронных сетей.
Источник
Создаем нейронную сеть для прогнозирования временного ряда

Интерес к нейронным сетям
Анализируя посещаемость нашего сайта, мы видим колоссальный интерес читателей к нейронным сетям. Данный инструментарий может решать целый набор задач, в том числе, прогнозировать временные ряды весьма эффективно. В частности, в своей диссертации я пишу следующим образом.
— В ряде работ [2],[36],[37] указано, что на сегодняшний день наиболее распространенными моделями прогнозирования являются авторегрессионные модели (ARIMAX), а также нейросетевые модели (ANN). В статье [3], в частности, утверждается: «Without a doubt ARIMA(X) and GRACH modeling methodologies are the most popular methodologies for forecasting time series. Neural networks are now the biggest challengers to conventional time series forecasting methods».
— Без сомнений модели ARIMA(X) и GARCH являются самыми популярными для прогнозирования временных рядов. В настоящее время главную конкуренцию данным моделям составляют модели на основе ANN.
У нас на сайте пока опубликован только один материал, посвященный нейронным сетям, в котором я давала советы по созданию сети. Интерес со стороны читателей заставляет меня более активно заниматься нейросетевым прогнозированием. Давайте попробуем шаг за шагом проделать работу по созданию, эффективному обучению и адаптации нейронной сети с тем, чтобы разобраться в нюансах нейросетевых моделей прогнозирования.
Первая нейронная сеть
Не стоит изобретать велосипед, а стоит взять готовый пример из книги Хайкина. Сама задача и ее решение подробно описаны в разделе 4.8 данной книги. Полный архив примеров для книги выложен у нас на форуме. Отдельно взятый рабочий пример можно скачать в архиве. Главный файл называется Create_ANN_step_0.m.
Приведенная программа решает задачу классификации. Прокомментирую текст основного файла.
Прогнозирование с помощью нейронной сети
Я взяла данный пример реализации нейронной сети, просмотрела внимательно содержание его функций и сделала свою нейронную сеть, которая прогнозирует торговый график по европейской территории РФ (далее ТГ) на 24 значения вперед. В архиве вы можете скачать, как полученный мною пример, так и исходные данные к нему. Основной файл называется Create_ANN_step_1.m
Шаг 1. Инициализация и исходные данные
Исходные данные по торговому графику содержатся в файле VOLUMES_EUR.mat и имеют значения за период с 01.09.2006 до 22.11.2011.
Обучение сети, то есть определение весов и смещений для всех нейронов я выполняю на периоде значений с 01.01.2010 по 31.12.2010.
В качестве тестового я выбрала период с 01.01.2011 по 22.11.2011.
Шаг 2. Предварительная обработка исходных данных
Из теории и из примера Хайкина я понимаю, что нейронная сеть работает со значениями временных рядов от 0 до 1. Исходные значения торгового графика в массиве VOLUMES_EUR, конечно, выходят далеко за этот диапазон. Для использования нейронной сети необходимо предварительно отмасштабировать исходный временной ряд, как показано на рисунках.
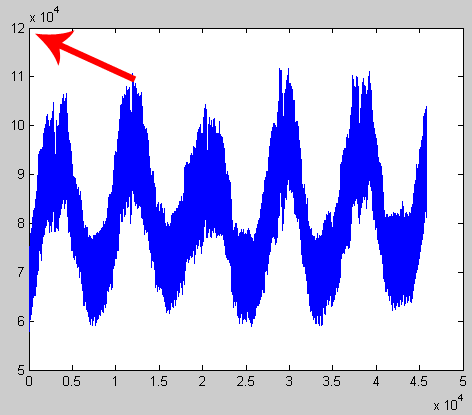
Рис 1. Предварительно мы имели значения от 57 847 до 111 720.
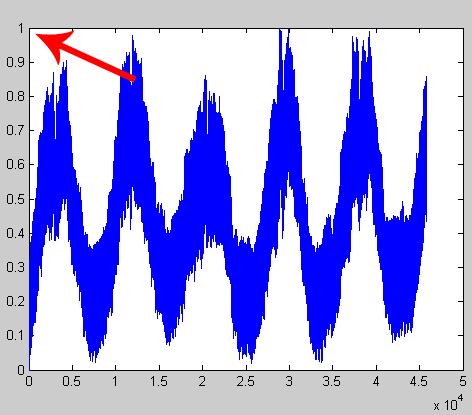
Рис 2. После масштабирования мы стали иметь значения от 0 до 1.
Шаг 3. Настройка нейронной сети
Так как в примере Хайкина содержалась трехслойная полносвязная нейронная сеть, то я на ней остановилась. Кроме того, из статей я знаю, что для прогнозирования энергопотребления чаще других используется именно трехслойная архитектура.
На вход нейронной сети я подаю 48 значений ТГ за двое предыдущих суток, скрытый слой после нескольких попыток стал содержать 72 нейрона, а на выходе мы получаем 24 прогнозных значений торгового графика на будущие сутки. Структура нейронной сети получилась следующая.
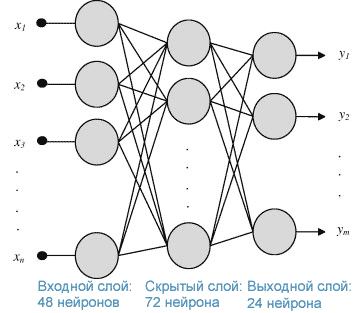
Рис 3. Структура разработанной нейронной сети.
После описания структуры указываются значения нескольких параметров нейронной сети (см файл Create_ANN_step_1.m). Не мудрствуя лукаво, оставила все значения, которые были установлены в примере Хайкина.
Шаг 4. Обучение сети
Двойной цикл по эпохам и внутренней корректировки весов я взяла в чистом виде из примера Хайкина. Такое обучение называется обучением нейронной сети по методу back propagation error (обратное распространение ошибки). Изменения внесены только в части формирования входа и выхода нейронной сети. Общие комментарии по ходу алгоритма приведены в тексте программы.
Шаг 5. Тестовое прогнозирование
На пятом шаге я формирую тестовый массив «T» и прогнозирую на полученной нейронной сети. Все прогнозирование в итоге сходится к нескольким строчкам кода.
По результатам прогноза я провожу инверсию масштаба.
Шаг 6. Оценка ошибки прогнозирования
На последнем шаге я вычисляю значения ошибки прогнозирования временных рядов MAE и MAPE.
Величина MAPE оставила около 4%, что показывает в целом адекватность разработанной нейросетевой модели прогнозирования. Однако мы знаем, что это далеко не предел точности! Аналогичное значение MAPE для того же самого временного ряда в отчете за аналогичный период (за 2011 год) составляет около 1.18% при использовании нашей внутренней модели прогнозирования. Подробности можно посмотреть в отчете Точность прогнозирования за истекшие периоды. В упомянутом отчете временной ряд назван для краткости ТГ ЕЦЗ (торговый график европейской ценовой зоны).
Результаты
Переделав пример Хайкина под нужны прогнозирования торгового графика (энергопотребления), мы получили новую нейронную сеть, трехслойную, полносвязную. Все параметры сети были из примера по книге Хайкина.
Созданная нейронная сеть обучается очень быстро: от 60 до 120 секунд в зависимости от мощности компьютера.
При тестовом прогнозировании на созданной нейронной сети получается прогноз торгового графика на сутки вперед с ошибкой MAPE ≅ 4%.
Исходный пример из книги Хайкина, а также мой пример нейронной сети для прогнозирования торгового графика европейской территории РФ с исходными данными вы можете скачать по приведенным ссылкам и попробовать решить свою задачу.
Уважаемые читатели, если вы скачали пример и пытаетесь на скорую руку прикрутить его к своей задаче, то обращаю ваше внимание на следующее.
- Если вы потратили меньше чем 6 месяцев на эти работы, то не ждите никакого адекватного результата. И полгода на приличный результат мало!
- Если у вас возник вопрос вроде «а где в коде то и се?», то имейте в виду, что я не буду впредь на эти вопросы отвечать — задавать их тут бесполезно. Для того, чтобы найти ответ на такого сорта вопрос нужно внимательно пошагово прогнать программу и разобраться.
- Если, не смотря на внимательный разбор кода примера, вопрос все равно остался, то задумайтесь, тем ли вы занимаетесь. Математическое моделирование — сфера деятельности, подходящая далеко не всем.
Похожие публикации
Комментарии

Добрый вечер, Ирина!
Я только начинаю заниматься изучением нейросетевого прогнозирования. Спасибо большое за Ваш пример, он очень полезен для меня.Могли бы подсказать, в результате работы программы только ошибка прогноза, а где можно сам результат посмотреть, «что было» — «что стало». Вывод куда то ведется или это нужно сделать? И например, чтобы мне загрузить свои тестовые данные, мне их нужно записать вручную в файл «VOLUMES_EUR.mat»?Прошу прощения за, возможно «наивные» вопросы, но я только начинаю изучать матлаб, пока что чайник в этом.. Был бы очень признателен, если поможете, ответите.
Сергей, добрый день!
Пожалуйста!
Могли бы подсказать, в результате работы программы только ошибка прогноза, а где можно сам результат посмотреть, «что было» — «что стало»
У нас с вами есть фраза в коде
Из нее следует, что и факт, и результат прогноза хранятся в переменной Result.
И например, чтобы мне загрузить свои тестовые данные, мне их нужно записать вручную в файл «VOLUMES_EUR.mat»?
Сергей, у вас довольно слабое понимание инструмента. Я бы посоветовала вам открыть и прочитать (хотя бы вводную часть) пособие по MATLABу. Многие ваши вопросы разрешатся.
mat — это встроенный формат MATLABа; чтобы сделать такой файл удобнее сначала подготовить данные в xls формате, а уж после загрузить xls в MATLAB буквально двумя строчками.

Добрый день, Ирина.
Подскажите пожалуйста есть ли смысл заниматься нейросетями на матлабе при очень большом объеме исходных данных. У меня объект — шахта, для обучения — входной вектор из аудиоряда с двух сотен микрофонов, длиной он в месяцы — но вход — кусочек в минуту. А выход — прогнозируемое событие: изменение технологических параметров, конкретно метанообразование). Итого объем данных по выборке более гигабайта.
Но эти детали наверное не очень важны.
Проще говоря, какова была размерность вашего файла для обучения для обучения в 40-60 секунд (можно просто к мегабайтах — мне этого будет достаточно)
Добрый день! У вас очень интересная задача, но данных действительно очень много, но это много не только для ANN, а вообще много. ANN — неплохой инструмент для подобной задачи, на мой взгляд. У меня в обучающей выборке было около
30 000 значений временного ряда. Это немного, конечно, по сравнению с вашими данными.
Работать с сырыми массивами в таком случае довольно сложно, но нужно исходить из задачи:
- если вы прогнозируете на несколько минут вперед, то разрешение должно остаться минутное;
- если прогноз более агрегированный, то и данные можно агрегировать.
Можете попробовать работать не с полным массивом, а с его кусочками, выборками. Можно их кластеризовать по некоторому признаку. Словом, не бойтесь объемов, научитесь обращаться с ними гибко.

добрый день, Ирина!
мы с програмистом практически повторили описанный алгоритм и получили аналогичные результаты по ошибкам на массиве EUR/USD. То есть все получилось и сработало. Но тут возник вопрос у программиста — а где собственно прогнозируемое окно? если Result вычисляется используя Index0 для тестового массива, то в этом масиве уже есть фактические данные , а прогнозируемое окно на 24 свечи вперед, означает что этих фактических данных еще нет, а прогнозируемое окно уже должно показать что «будет». Означает ли это, что мы должны поставить в тестовом массиве Index0 нули на величину одного окна в 24 свечи, а затем сравнить с фактическими данными поступившими в это окно?
будем благодарны за ответ
Илья, добрый день!
Смотрите внимательно, Result получается без использования Index0. Сначала берутся предыдущие дни (h-24; h-48), их индексы хранятся в Index1 и Index2.
Затем на основании этих индексов фомируется матрица T, где в 2 и 3 столбец записываются исторические значения.
А затем они используются для формирования входа сети.
Если все это проделать в дебаг режиме, то ответ на ваш вопрос будет быстро понятен.

Для использования нейронной сети необходимо предварительно отмасштабировать исходный временной ряд, как показано на рисунка
Добрый День. А можно с этого момента по подробней.
Каким методом можно сделать масштабирование? Пожалуйста — направте на литературу или приведите пример как это делаеться и почему. Если у меня данные в диапазано от 0 до 3 или 2 , как отмашт. к 0 и 1?
Скачиваете код примера в Matlab, смотрите на строки масштабирования и разбираетесь — в примере оно реализовано, достаточно разобраться каким образом.

Здравствуйте еще раз.По ходу разберательства сформировались еще несколько вопросов.Зачем на вход сети подавать данные за два прошедших дня (Xi-1, Xi-2)?почему бы просто не подать на вход Xi, и пытаться обучая сеть на выходе получить Xi.Далее не совсем понятно почему при формировании матрицы весов:для скрытого слоя W1 = randn(NumberOfHiddenNeurons, NumberOfInputNeurons+1); матрица строится по строкам по количеству нейронов скрытого слоя, по столбцам по количеству входных нейронов. Не понятно почему так,ведь по смыслу связьидет от входного к скрытому. вроде как должно быть наоборот W1 = randn(NumberOfInputNeurons, NumberOfHiddenNeuron+1);. В таком же виде строится матрица и для весов выходного слоя W2 = randn(NumberOfOutputNeurons, NumberOfHiddenNeurons+1); Также не ясно почему столбцов в матрице весов на 1 больше W1 = randn(NumberOfHiddenNeurons, NumberOfInputNeurons+1),по коду ясно, что это столбец загоняется в переменную b1/b2, которая в последствии используется для прогнозирования временного ряда.И вот собственно вопрос, что эта за переменная b1, зачем она нужна, потому как точность прогноза без нее падает ощутимо!
почему бы просто не подать на вход Xi, и пытаться обучая сеть на выходе получить Xi
Если сеть обучена по принципу «из Xi получить Xi», то как получить прогноз?
Далее не совсем понятно почему при формировании матрицы весов.
Эти вопросы касаются понимания работы сети. Смотрите подробности в Хайкине. Мой пример основан на примере, который подробно разбирается в указанной книге. И вообще, это замечательная книга по нейронным сетям. Кроме того, можете посмотреть мой краткий материал по нейронным сетям.
Скачал ваш код. Во многом разобрался. Все понятно и доступно.
Но есть маленькое WHY?
24 – это NumberOfOutputNeurons?
Почему 24… не пойму..
И еще. Если я хочу увеличить число входов (нейронов) нужно ли увеличивать число циклов епох или это нужно делать только экспериментально. То есть смотреть не увеличивается ошибка…?
Еще раз спасибо Вам за статью и Ваши ответы.
Так как исходный ряд Data, а также переменная P имеют значения в почасовом разрешении, а далее (ниже) в цикле обучения сети я перебираю сутки, то мне просто нужно из общего числа часов получить число суток. Вот так появилось 24 — в сутках 24 часа. Даты с переходами времени здесь не учитываются.
Здравствуйте Ирина!Спасибо Вам за отличную статью! на ру кластере аналога ей нет, очень мало примеров прогнозирования временных рядов с помощью нейронных сетей!Скажите пожалуйста, нет ли у Вас возможности, адаптировать код под более популярный язык программирования java или С++?
Виктор, спасибо за приятные слова.
К сожалению, у меня нет примера на высокоуровнем языке программирования, потому как я ими очень слабо владею. Как говорит мой партнер Сергей: отличный математик не бывает отличным программистом. Работаю в основном двух пакетах: matlab и R.
Ваш партнер не прав) Задачи решаемые программированием часто пересекаются с задачами математики.
Я его мнению очень доверяю и потому работаю над такими проблемами в паре с программистом. Еще не встречала приличного математика, который свободно владеет приемами качественного ООП.

Доброго времени суток. Возникла идея пргнозирования исхода теннисных матчей на основе нейроннных сетей. Хотелось бы спросить, где у вас в программе можно найти заданные выходы соответствующих входов в сети на этапе обучения? Насколько я понимаю именно с заданными выходами и осуществляется сравнение полученных выходов на этапе обучения? Также непонятно, почему при прогнозировании на этапе теста используются предыдущие входы? Ведь на этапе обучения мы получиили нужные нам веса и теперь остается лишь поставлять новые значения входов? Хотелось бы узнать этот момент подробнее. И хотелось бы у вас попросить совета. В строящейся сети будет использовано 50 входных нейронов, 150 скрытых. Задача программы выдавать номер игрока-победителя (либо 1 либо 2). Таким образом как результат необходимо получить сеть с одним выходом. Возможно ли это? Ведь номер победителя будет являться логической величиной, полученной на основе входных характеристик каждых из игроков (то есть грубо говоря, если характеристики игрока 1 лучше игрока 2, то на выходе получаем -1, в обратном случае -2). Может ли нейронная сеть на выходе давать логическую величину? И как будет осуществляться обучение? Ведь получаемые числа будут сравниваться на этапе обучения опять же с логической величиной известных результатов. Просто можно ведь сделать два выхода сети: процент соответствия игроку 1 категории «победитель» и процент соответствия игроку 1 категории «проигравший». Но тогда непонятно как обучать. Ведь в известных результатах базы на этапе обучения есть только номер победителя. Надеюсь понятно изложил свои мысли. Заранее благодарен!
Хотелось бы спросить, где у вас в программе можно найти заданные выходы соответствующих входов в сети на этапе обучения? Насколько я понимаю именно с заданными выходами и осуществляется сравнение полученных выходов на этапе обучения?
Уважаемые читатели, я не только к автору сего вопроса обращаюсь, а вообще к посетителям. Я выложила пример с пояснениями и исходными данными не для того, чтобы вам тут пошагово каждый раз заново пояснять где чего. Мне такого сорта вопросы надоели до невозможности! Сядьте, наконец, и терпеливо разберитесь! Пример сделан много лет назад, чтобы ответить на ваши вопросы, мне нужно его открывать, смотреть, прогонять в дебаггере. Вы-то при этом чем заняты?
Также непонятно, почему при прогнозировании на этапе теста используются предыдущие входы? Ведь на этапе обучения мы получиили нужные нам веса и теперь остается лишь поставлять новые значения входов?
Если вы внимательно все это пошагово прогоните, то поймете, что это не так. И ваш вопрос лишь от невнимательности.
Таким образом как результат необходимо получить сеть с одним выходом. Возможно ли это?
Может ли нейронная сеть на выходе давать логическую величину?
Источник

