Алгоритм CELP(линейное предсказание с мультикодовым управлением)
Алгоритм CELPоснован на линейной авторегрессионной модели процесса формирования и восприятия речи и входит в группу так называемых методов анализа через синтез (или анализ-синтез), реализующих современные и эффективные алгоритмы информационного сжатия речевых сигналов [9].
Речь может быть представлена моделью авторегрессии (AR) [10]:
. (16)
Каждый отсчёт представлен в виде линейной комбинации предшествующих отсчётов плюс белый шум. Весовые коэффициенты являются коэффициентами линейного предсказания (см. п. 2.1.1.). Эти коэффициенты используются в алгоритме CELP для кодирования речевого сигнала [10]. Входной сигнал разбивается на кадры длиной 10-20 мс, в каждом из которых содержится по отсчётов. Каждый кадр разбивается на меньшие блоки, по отсчётов в каждом (это значение равно размерности вектора квантования). Такие блоки называют подкадрами. Для каждого кадра находятся свои коэффициенты линейного предсказания. Спектр , полученный по вышеописанной модели, приблизительно соответствует спектру кадра входного речевого сигнала.
Воспользовавшись z-преобразованием для (16), получим:
Из уравнений (16) и (17) можно сделать вывод, что если пропустить белый шум через фильтр , можно сгенерировать – воспроизведениеречевого сигнала, близкого квходному.
Общая схема CELP кодера показана на рис. 5. Имеется кодовая книга длины размерности , доступная как кодеру, так и декодеру. Кодовые векторы имеют компоненты, выбранные все независимо из стандартного нормального распределения , поэтому каждый из кодовых векторов приблизительно имеет спектр белого шума. Каждый подкадр входной речи (по отсчётов) обрабатывается следующим образом: каждый кодовый вектор пропускается через 2 фильтра (LPC фильтр и Pitch фильтр ) и полученный на выходе сигнал сравнивается с отсчётами речи. Кодовый вектор, чей выход наиболее близок к входной речи (наименьшее – MeanSquaredError), выбирается для представления подкадра.
Рис.5. Общая схема CELP, минимизация ошибки посредством выбора лучшего вхождения кодовой книги [10]
Первый фильтр ( ) описывается уравнением (17). Он формирует спектр белого шума кодового вектора, имеющий сходство со спектром входного речевого сигнала. С другой стороны, во временной области фильтр содержит кратковременные корреляции (корреляции с предыдущими отсчётами) в последовательности белого шума. Помимо этого известно, что участки с вокализованной речью проявляют длительную периодичность. Этот период (Pitch, высота тона) включён в синтезированный спектр посредством Pitch фильтра . Поведение временной области этого фильтра может быть выражено следующим образом:
где – входной сигнал, –сигнал на выходе, –высота тона.
Речь, синтезированная фильтром, масштабируется соответствующим коэффициентом усиления (gain) для того, чтобы сделать энергию равной энергии входной речи.
Обобщая вышесказанное: на каждом кадре речевого сигнала вычисляются коэффициенты линейного предсказания и высота тона, обновляются фильтры; на каждом подкадре речевого сигнала ( отсчётов) кодовый вектор, который производит «наилучший» фильтрованный выход, выбирается для представления подкадра.
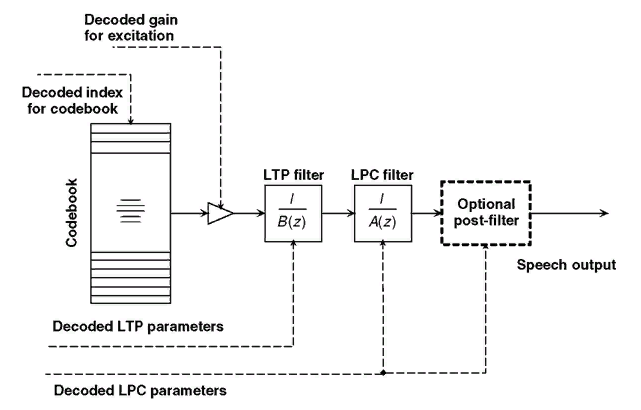
Декодер получает индексы выбранных кодовых векторов и квантованное значение коэффициента усиления для каждого подкадра. Значения коэффициентов линейного предсказания и высоты тона также подлежат квантованию и посылаются на каждом кадре для воссоздания фильтров в декодере. Речевой сигнал воссоздаётся в декодере посредством пропускания выбранных кодовых векторов через фильтры [10].
Рис.6. Основная концепция процесса кодированиявокодераCELP [16]
Рис.7. Основная концепция процесса декодирования вокодераCELP [16]
На рис. 6, 7 показана диаграмма, иллюстрирующая концепцию анализ-синтез CELP вокодера. Остановимся более подробно на каждом из компонентов данного вокодера.
Длина каждого кадра берётся равной 20 мс в целях использования для анализа речевого тракта (160 отсчётов с частотой дискретизации 8 кГц), длина блока (подкадра) – 5 мс (40 отсчётов) для определения возбуждения. Декодеру необходимо передать 5 параметров:
· Коэффициенты линейного предсказания a;
· Коэффициент возбуждения G;
· Коэффициент Pitch фильтра;
· Задержку Pitch (высоты тона);
· Индекс кодовой книги.
Алгоритм CELP наиболее эффективно применяется при передаче речевого сигнала в диапазоне скоростей от 4 до 16 Кбит/с.Длина кадра N равна 160 отсчётам, длина подкадраL равна 40 отсчётам. Порядок LP-анализа Mравен 10 (но не всегда). Оценка числа отсчётовв периоде основного тона принимает значения из отрезка [16; 160].
Рассмотрим 2 варианта – 9.6 kbpsCELP вокодер и 16 kbpsCELPвокодер.У первого варианта скорость передачи 9600bps, у второго – 16000 bps.Таблицы кодирования параметров для каждого вокодера приведены ниже [10].
Кодирование параметров 9.6 kbpsCELP вокодера в битах.
Название параметра
Нотация параметра
Число бит на параметр
Число бит на кадр
Индекс кодовой книги
k
10
40
Коэффициенты линейного предсказания
6
60
Коэффициент усиления
G
7
28
Коэффициенты Pitch фильтра
b
8
32
Запаздывание Pitch фильтра
P
8
32
Итого
Кодирование параметров 16 kbpsCELP вокодера в битах.
Название параметра
Нотация параметра
Число бит на параметр
Число бит на кадр
Индекс кодовой книги
k
10
40
Коэффициенты линейного предсказания
12
144
Коэффициент усиления
G
13
52
Коэффициенты Pitch фильтра
b
13
52
Запаздывание Pitch фильтра
P
8
32
Итого
Можно заметить, что 16 kbpsCELPвокодер для каждого кадра речевого сигнала использует 12 коэффициентов предсказания . Кроме того, под каждый параметр выделяется большее количество бит, что обеспечивает лучшее качество синтезированного сигнала по сравнению с 9.6 kbpsCELP вокодером.
Дата добавления: 2018-06-27 ; просмотров: 669 ; Мы поможем в написании вашей работы!
Источник
Линейное предсказание с кодовым возбуждением — Code-excited linear prediction
Линейное предсказание с кодовым возбуждением ( CELP ) — это алгоритм кодирования речи с линейным предсказанием , первоначально предложенный Манфредом Р. Шредером и Бишну С. Аталом в 1985 году. В то время он обеспечивал значительно лучшее качество, чем существующие алгоритмы с низкой скоростью передачи данных, такие как остаточные алгоритмы. -excited линейного предсказания (ОВЛП) и кодирования с линейным предсказанием (LPC) вокодеры (например, FS-1015 ). Наряду с его вариантами, такими как алгебраический CELP , ослабленный CELP , CELP с малой задержкой и линейное прогнозирование с векторной суммой , в настоящее время это наиболее широко используемый алгоритм кодирования речи. Он также используется в кодировании речи MPEG-4 Audio . CELP обычно используется как общий термин для класса алгоритмов, а не для конкретного кодека.
Содержание
Введение
Алгоритм CELP основан на четырех основных идеях:
Использование модели источника-фильтра при формировании речи посредством линейного предсказания (LP) (см. Учебник «Алгоритм кодирования речи»);
Использование адаптивной и фиксированной кодовой книги в качестве входа (возбуждения) модели LP;
Выполнение поиска в замкнутом цикле в «перцептуально взвешенной области».
Применение векторного квантования (VQ)
Исходный алгоритм, смоделированный в 1983 году Шредером и Аталом, требовал 150 секунд для кодирования 1 секунды речи при запуске на суперкомпьютере Cray-1 . С тех пор более эффективные способы реализации кодовых книг и улучшения вычислительных возможностей сделали возможным запуск алгоритма во встроенных устройствах, таких как мобильные телефоны.
CELP декодер
Прежде чем исследовать сложный процесс кодирования CELP, мы представим здесь декодер. На рисунке 1 показан общий декодер CELP. Возбуждение создается путем суммирования вкладов от фиксированной (также известной как стохастический или инновационный) и адаптивной (также известной как шаг) кодовых книг:
е [ п ] знак равно е ж [ п ] + е а [ п ] <\ Displaystyle е [п] = е_ <е>[п] + е_ <а>[п] \,>
где является фиксированной (ака стохастические или инновации) вклад кодовой книги и является адаптивным ( шаг ) вклад кодовой книги. Фиксированная кодовая книга — это словарь векторного квантования, который (неявно или явно) жестко закодирован в кодеке. Эта кодовая книга может быть алгебраической ( ACELP ) или сохраняться явно (например, Speex ). Записи в адаптивной кодовой книге состоят из отложенных версий возбуждения. Это позволяет эффективно кодировать периодические сигналы, например звонкие звуки. е ж [ п ] <\ displaystyle e_ [n]> е а [ п ] <\ Displaystyle е_ <а>[п]>
Фильтр, формирующий возбуждение, имеет всеполюсную модель формы , которая называется фильтром прогнозирования и получается с использованием линейного прогнозирования ( алгоритм Левинсона – Дурбина ). Всеполюсный фильтр используется потому, что он хорошо отображает голосовой тракт человека и потому, что его легко вычислить. 1 / А ( z ) <\ displaystyle 1 / A (z)> А ( z ) <\ Displaystyle А (г)>
Кодировщик CELP
Основной принцип, лежащий в основе CELP, называется анализом путем синтеза (AbS) и означает, что кодирование (анализ) выполняется путем перцепционной оптимизации декодированного (синтезируемого) сигнала в замкнутом цикле. Теоретически лучший поток CELP можно получить, попробовав все возможные битовые комбинации и выбрав ту, которая дает декодированный сигнал с наилучшим звучанием. Очевидно, что на практике это невозможно по двум причинам: требуемая сложность выходит за рамки любого доступного в настоящее время оборудования, и критерий выбора «наилучшее звучание» предполагает наличие слушателя-человека.
Чтобы достичь кодирования в реальном времени с использованием ограниченных вычислительных ресурсов, поиск CELP разбивается на более мелкие, более управляемые, последовательные поиски с использованием простой функции перцепционного взвешивания. Обычно кодирование выполняется в следующем порядке:
Коэффициенты линейного предсказания (LPC) вычисляются и квантуются, обычно как линейные спектральные пары (LSP).
Выполняется поиск адаптивной кодовой книги (основного тона), и ее вклад удаляется.
Выполняется поиск в фиксированной (инновационной) кодовой книге.
Взвешивание шума
Большинство (если не все) современных аудиокодеков пытаются сформировать шум кодирования так, чтобы он появлялся в основном в частотных областях, где ухо не может его обнаружить. Например, ухо более устойчиво к шуму в более громких частях спектра и наоборот. Вот почему вместо минимизации простой квадратичной ошибки CELP минимизирует ошибку для перцепционно взвешенной области. Весовой фильтр W (z) обычно получается из фильтра LPC с использованием расширения полосы пропускания :
W ( z ) знак равно А ( z / γ 1 ) А ( z / γ 2 ) <\ Displaystyle W (z) = <\ гидроразрыва )> )>>>
 . (16)
. (16) отсчётов плюс белый шум. Весовые коэффициенты
отсчётов плюс белый шум. Весовые коэффициенты  являются коэффициентами линейного предсказания (см. п. 2.1.1.). Эти коэффициенты используются в алгоритме CELP для кодирования речевого сигнала [10]. Входной сигнал разбивается на кадры длиной 10-20 мс, в каждом из которых содержится по
являются коэффициентами линейного предсказания (см. п. 2.1.1.). Эти коэффициенты используются в алгоритме CELP для кодирования речевого сигнала [10]. Входной сигнал разбивается на кадры длиной 10-20 мс, в каждом из которых содержится по  отсчётов. Каждый кадр разбивается на меньшие блоки, по
отсчётов. Каждый кадр разбивается на меньшие блоки, по 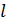 отсчётов в каждом (это значение равно размерности вектора квантования). Такие блоки называют подкадрами. Для каждого кадра находятся свои коэффициенты линейного предсказания. Спектр
отсчётов в каждом (это значение равно размерности вектора квантования). Такие блоки называют подкадрами. Для каждого кадра находятся свои коэффициенты линейного предсказания. Спектр 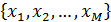 , полученный по вышеописанной модели, приблизительно соответствует спектру кадра входного речевого сигнала.
, полученный по вышеописанной модели, приблизительно соответствует спектру кадра входного речевого сигнала.
 через фильтр
через фильтр 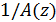 , можно сгенерировать
, можно сгенерировать 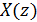 – воспроизведениеречевого сигнала, близкого квходному.
– воспроизведениеречевого сигнала, близкого квходному. размерности
размерности  , поэтому каждый из кодовых векторов приблизительно имеет спектр белого шума. Каждый подкадр входной речи (по
, поэтому каждый из кодовых векторов приблизительно имеет спектр белого шума. Каждый подкадр входной речи (по 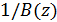 ) и полученный на выходе сигнал
) и полученный на выходе сигнал  сравнивается с отсчётами речи. Кодовый вектор, чей выход наиболее близок к входной речи (наименьшее
сравнивается с отсчётами речи. Кодовый вектор, чей выход наиболее близок к входной речи (наименьшее  – MeanSquaredError), выбирается для представления подкадра.
– MeanSquaredError), выбирается для представления подкадра.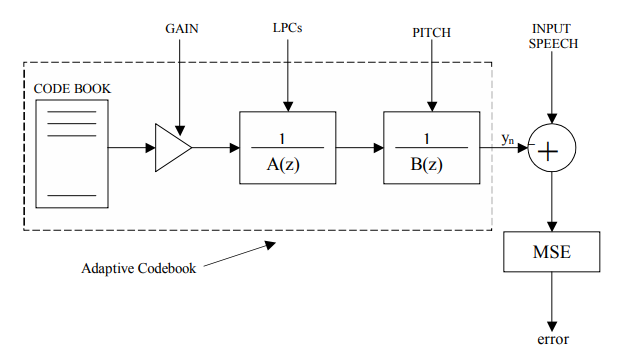
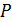 предыдущими отсчётами) в последовательности белого шума. Помимо этого известно, что участки с вокализованной речью проявляют длительную периодичность. Этот период (Pitch, высота тона) включён в синтезированный спектр посредством Pitch фильтра
предыдущими отсчётами) в последовательности белого шума. Помимо этого известно, что участки с вокализованной речью проявляют длительную периодичность. Этот период (Pitch, высота тона) включён в синтезированный спектр посредством Pitch фильтра  , (18)
, (18) – входной сигнал,
– входной сигнал,  –сигнал на выходе,
–сигнал на выходе,  –высота тона.
–высота тона.
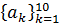

 . Кроме того, под каждый параметр выделяется большее количество бит, что обеспечивает лучшее качество синтезированного сигнала по сравнению с 9.6 kbpsCELP вокодером.
. Кроме того, под каждый параметр выделяется большее количество бит, что обеспечивает лучшее качество синтезированного сигнала по сравнению с 9.6 kbpsCELP вокодером.


