Кодирование с линейным прогнозированием — Linear predictive coding
Кодирования с линейным предсказанием ( LPC ) представляет собой метод , используемый в основном в аудио обработки сигналов и речевой обработки для представления спектральной огибающей в виде цифрового сигнала из речи в сжатом виде, с использованием информации о виде линейной модели прогнозирования . Это один из самых мощных методов анализа речи и один из наиболее полезных методов кодирования речи хорошего качества с низкой скоростью передачи данных, обеспечивающий высокоточные оценки параметров речи. КЛП является наиболее широко используемым методом в кодировании речи и синтеза речи .
СОДЕРЖАНИЕ
Обзор
LPC исходит из предположения, что речевой сигнал генерируется зуммером на конце трубки (для озвученных звуков), со случайным добавлением шипящих и хлопающих звуков (для глухих звуков, таких как свистящие и взрывные звуки ). Несмотря на кажущуюся грубость, эта модель на самом деле является близким приближением к реальности производства речи. Голосовая щель (пространство между голосовыми складками) производит шум, который характеризуется своей интенсивностью ( громкость ) и частота ( основной тон). Голосовой тракт (горло и рот) образует трубку, которая характеризуется ее резонансов; эти резонансы дают начало формантам или расширенным частотным полосам в производимом звуке. Шипение и хлопки производятся языком, губами и горлом во время свистящих и взрывных звуков.
LPC анализирует речевой сигнал, оценивая форманты, удаляя их эффекты из речевого сигнала и оценивая интенсивность и частоту оставшегося шума. Процесс удаления формант называется обратной фильтрацией, а оставшийся сигнал после вычитания отфильтрованного смоделированного сигнала называется остатком.
Числа, которые описывают интенсивность и частоту гудения, формант и остаточного сигнала, могут быть сохранены или переданы в другое место. LPC синтезирует речевой сигнал, обращая процесс: используйте параметры гудка и остаток для создания исходного сигнала, используйте форманты для создания фильтра (который представляет трубку) и пропустите источник через фильтр, в результате чего получится речь.
Поскольку речевые сигналы меняются со временем, этот процесс выполняется на коротких фрагментах речевого сигнала, которые называются кадрами; обычно от 30 до 50 кадров в секунду дают разборчивую речь с хорошим сжатием.
Ранняя история
Линейное прогнозирование (оценка сигнала) восходит как минимум к 1940-м годам, когда Норберт Винер разработал математическую теорию для расчета лучших фильтров и предикторов для обнаружения сигналов, скрытых в шуме. Вскоре после того, как Клод Шеннон установил общую теорию кодирования, работа над предиктивным кодированием была проведена Ч. Чапином Катлером , Бернардом М. Оливером и Генри К. Харрисоном. Питер Элиас в 1955 году опубликовал две статьи о кодировании сигналов с предсказанием.
Линейные предикторы применялись к анализу речи независимо Фумитадой Итакурой из Университета Нагоя и Сюдзо Сайто из Nippon Telegraph and Telephone в 1966 году и в 1967 году Бишну С. Аталем , Манфредом Р. Шредером и Джоном Бургом. Итакура и Сайто описали статистический подход, основанный на оценке максимального правдоподобия ; Атал и Шредер описали подход адаптивного линейного предсказателя ; Бург изложил подход, основанный на принципе максимальной энтропии .
В 1969 году Итакура и Сайто представили метод, основанный на частичной корреляции (PARCOR), Глен Каллер предложил кодирование речи в реальном времени, а Бишну С. Атал представил речевой кодер LPC на Ежегодном собрании Акустического общества Америки . В 1971 году компания Philco-Ford продемонстрировала LPC в реальном времени с использованием 16-битного оборудования LPC ; было продано четыре единицы. Технология LPC была развита Бишну Аталом и Манфредом Шредером в 1970–1980-х годах. В 1978 году Атал и Вишванат и др. BBN разработала первый алгоритм LPC с переменной скоростью . В том же году Атал и Манфред Р. Шредер из Bell Labs предложили речевой кодек LPC, называемый адаптивным предсказательным кодированием , в котором использовался алгоритм психоакустического кодирования, использующий маскирующие свойства человеческого уха. Позже это стало основой для техники перцептивного кодирования , используемой форматом сжатия звука MP3 , введенным в 1993 году. Линейное предсказание с кодовым возбуждением (CELP) было разработано Шредером и Аталом в 1985 году.
LPC является основой для технологии передачи голоса по IP (VoIP). В 1972 году Боб Кан из ARPA вместе с Джимом Форги ( Lincoln Laboratory , LL) и Дэйвом Уолденом ( BBN Technologies ) начали первые разработки в области пакетной речи, которые в конечном итоге привели к технологии передачи голоса по IP. Согласно неофициальной истории Лаборатории Линкольна, в 1973 году Эд Хофстеттер реализовал первый LPC в реальном времени со скоростью 2400 бит / с. В 1974 году была осуществлена первая двусторонняя пакетная речевая связь LPC в реальном времени через ARPANET со скоростью 3500 бит / с между лабораторией Каллера-Харрисона и Линкольна. В 1976 году была проведена первая конференция LPC по ARPANET с использованием сетевого голосового протокола между Каллером-Харрисоном, ISI, SRI и LL со скоростью 3500 бит / с.
Представления коэффициентов LPC
LPC часто используется для передачи информации о спектральной огибающей, и поэтому он должен быть устойчивым к ошибкам передачи. Прямая передача коэффициентов фильтра ( определение коэффициентов см. В линейном прогнозировании ) нежелательна, поскольку они очень чувствительны к ошибкам. Другими словами, очень маленькая ошибка может исказить весь спектр или, что еще хуже, небольшая ошибка может сделать фильтр предсказания нестабильным.
Существуют более сложные представления, такие как логарифмические отношения площадей (LAR), разложение по парам спектральных линий (LSP) и коэффициенты отражения . Среди них особенно популярно разложение LSP, поскольку оно обеспечивает стабильность предсказателя, а спектральные ошибки являются локальными для малых отклонений коэффициентов.
Приложения
КЛП является наиболее широко используемым методом в кодировании речи и синтеза речи . Обычно он используется для анализа речи и ресинтеза. Телефонные компании используют его как форму сжатия голоса, например, в стандарте GSM . Он также используется для безопасной беспроводной связи, где голос должен быть оцифрован , зашифрован и отправлен по узкому голосовому каналу; ранний пример этого является правительство США Навахо я .
Синтез LPC может использоваться для создания вокодеров, в которых музыкальные инструменты используются в качестве сигнала возбуждения для изменяющегося во времени фильтра, оцениваемого по речи певца. Это довольно популярно в электронной музыке . Пол Лански сделал известное компьютерное музыкальное произведение без всякой путаницы, используя кодирование с линейным предсказанием. [1] LPC 10-го порядка использовался в популярной обучающей игрушке Speak & Spell 1980-х годов .
LPC предикторы используются в Сокращенно , MPEG-4 ALS , FLAC , ШЕЛКОВОМ аудиокодека и других без потерь аудио кодеков.
LPC уделяется некоторое внимание как инструменту для тонального анализа скрипок и других струнных музыкальных инструментов.
Источник
Анализ речи на основе линейного предсказания
Анализ речи на основе линейного предсказания базируется на использовании модели речевого сигнала, представленной на рис.4.1, Основная задача метода состоит в том, чтобы по наблюдениям последовательности отсчетов речевого сигнала s[n] определить коэффициенты a[k] цифрового фильтра указанной модели [14,15,17].
Найденные значения коэффициентов, которые называют коэффициентами линейного предиктивного кодирования (ЛПК), могут применяться при определении частоты основного тона, при кодировании речи в соответствии с АДИКМ, в задачах распознавания и синтеза речи.
Главное допущение метода линейного предсказания состоит в том, что речевой отсчет на выходе голосового тракта s[n] может быть предсказан по линейной комбинации своих предыдущих значений и значению сигнала и [п]
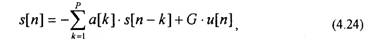
где G — коэффициент усиления; Р — порядок линейного предсказателя. Е этом случае передаточная функция предсказателя соответствует передаточной функции рекурсивного фильтра
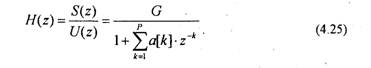
Определение коэффициентов линейного предсказания речи имеет прямое отношение к спектральному анализу, основанному на использовании АР-модели. Вместе с тем, использование модели, приведенной на рис.4.1, вносит некоторую специфику. Поэтому рассмотрим оценивание ЛПК речи подробнее. Так как отсчеты возбуждающей последовательности и[п] неизвестны, то последовательность s[n] может быть предсказана только по своим предыдущим значениям
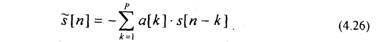
Ошибка предсказания в этом случае будет равна
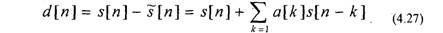
Определим коэффициенты a[k] таким образом, чтобы сумма квадратов ошибок предсказания была минимальна
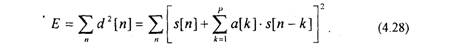
Для минимизации (4.28) найдем частные производные (4.28) по a[k] и приравняем их к нулю
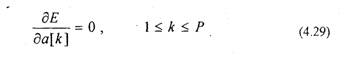
В результате получим систему уравнений
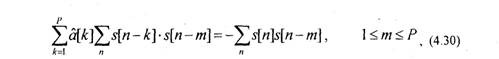
где a[k] -оценки коэффициентов a[k].
В общем случае суммирование в (4.30) должно выполняться по всем значениям п. Однако на практике суммирование по я в уравнении (4.30) выполняют для ограниченного числа отсчетов s[n], чтобы соблюдалось условие стационарности s[n]. Для этого ограничивают последовательность s[n] с помощью окна w[n]
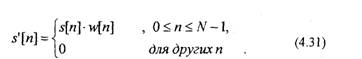 |
Тогда систему уравнений (4.30) можно переписать в виде
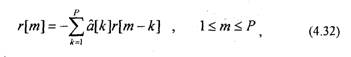
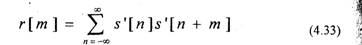
автокорреляционная функция ограниченной последовательности s'[n].
Так как автокорреляционная функция является четной, т.е. г[от]=г[-/п],
то (4.32) можно записать в матричной форме ;
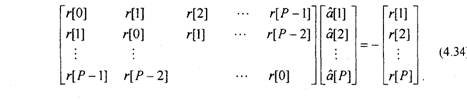
Матричное уравнение (4.34) имеет структуру аналогичную уравнению (2.35) и может быть решено с помощью рекурсивного алгоритма Левинсона — Дарбина. В соответствии с этим алгоритмом решение для предсказателя т-го порядка получается на основе решения для предсказателя т-\ порядка. Формально алгоритм определяется следующими соотношениями 4,14,15,171:
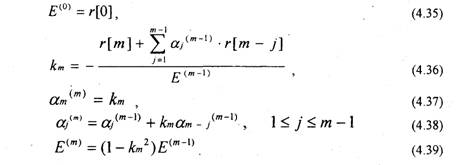
Уравнения (4.35 — 4.39) решаются рекурсивно для т=1, 2, . Р: Отметим, что для от=1 параметр а^ = k\ = r[l]/r[0] и. Е^ = (1 — k^)r[0]. Для конечного решения порядка Р коэффициенты линейного предсказания будут равны
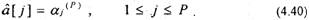
Коэффициенты km называются коэффициентами отражения. Е представляет сумму квадратов ошибки предсказания для предсказателя т-го порядка. Автокорреляционную функцию последовательности s'[n] оценивают на основе соотношения: 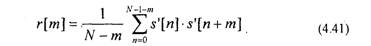
Линейное предсказание речи можно использовать для определения частотной характеристики голосового тракта
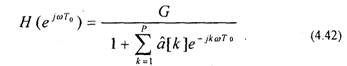
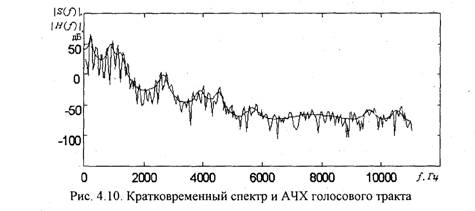
Данная характеристика соответствует медленно меняющейся составляющей кратковременного спектра речевого сигнала. На рис. 4.10 представлен кратковременный спектр речевого сигнала и АЧХ голосового тракта, вычисленная с помощью (4.42). Порядок фильтра Р=28. На графике АЧХ хорошо представлены форманты.
Недостатком рассмотренного метода определения ЛПК является необходимость вычисления матрицы автокорреляций. Кроме этого, если вычисленные значения ЛПК применяются при синтезе речи в соответствии со схемой, показанной на рис.4.1, то возникают вопросы обеспечения устойчивости цифрового рекурсивного фильтра высокого порядка.
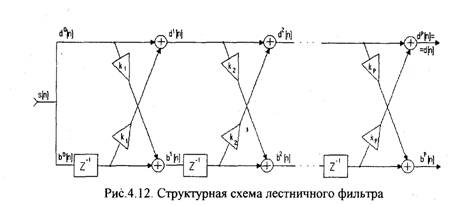
В настоящее время развит класс методов, которые оценивают ЛПК непосредственно по отсчетам последовательности s[n] и которые лучше приспособлены для решения задач синтеза речи. Эти методы базируются на использовании лестничного фильтра [17].
Рассмотрим алгоритм Левинсона-Дарбина. Параметры aii представляют коэффициенты предсказывающего фильтра т-го порядка. Определим передаточную функцию
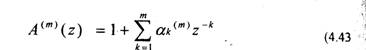
Эта передаточная функция соответствует инверсному фильтру и являете» ‘^j обратной по отношению к передаточной функции предсказателя (4.25). Е ‘ соответствии с (4.27) на вход инверсного фильтра поступает речевой сигнал s[n], а на выходе формируется ошибка предсказания. Ошибка предсказания;
для предсказателя т-го порядка будет равна 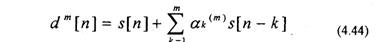
Найдем z-преобразование (4.44). Тогда
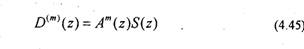
Подставив (4.38) в (4.43), получим
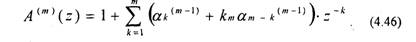
Отсюда получаем рекурсивное выражение для вычисления A»»‘\z)
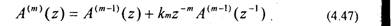
Подставляя (4.47) в (4.45), получаем выражение для ошибки предсказания
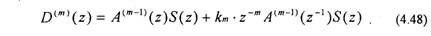
Первый член в (4.48) соответствует ошибке предсказания для предсказателя (т-1 )-го порядка. Для второго члена в (4.48) без km введем обозначение
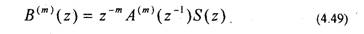
Выражению (4.49) соответствует разностное уравнение
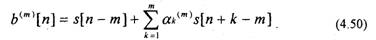
Данное уравнение соответствует обратному предсказанию, т.е. оно позволяет предсказать отсчет по предстоящим отсчетам s[(n-m)+k] и (рис.4.11). 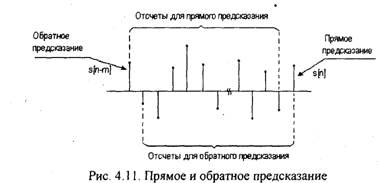
Сравнивая (4.50) и (4.44), отмечаем, что b»‘[n] соответствует ошибке обратного предсказания. Таким образом, ошибка прямого предсказания (4.48) может быть представлена в виде
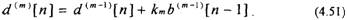
Выполнив аналогичные преобразования для (4.50), получим симметричное выражение для ошибки обратного предсказания
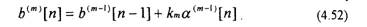
Уравнения (4.51) и (4.52) являются рекуррентными и определяют ошибки предсказаний для предсказателя т-го порядка через ошибки предсказания для предсказателя (m-l)-ro порядка. При этом для предсказателя нулевого порядка

Уравнения (4.51) и (4.52) соответствуют лестничному фильтру и могут быть представлены в виде структурной схемы, изображенной на рис.4.12.
Коэффициенты отражения km могут вычисляться в соответствии с уравнениями (4.35 — 4.39). Однако имеется и иная возможность. В [11,36] показано, что коэффициенты отражений можно вычислять через ошибки предсказания d»[n\ и &»*[«] в соответствии с соотношением
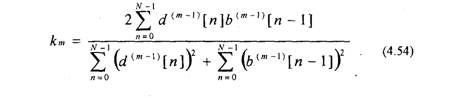
Выражение (4.54) является нормированной корреляционной зависимостью и показывает степень корреляции между ошибкой прямого предсказания и ошибкой обратного предсказания. Поэтому коэффициенты km иногда называют коэффициентами частной корреляции. Уравнение (4.54) может использоваться вместо уравнения (4.36) при оценивании коэффициентов линейного предсказания.
Оценки коэффициентов km лестничного фильтра, вычисленные с помощью (4.54), будут находиться в диапазоне —1 r и Г — задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания (/л-М, то в соответствии с (4.55) ошибка долговременного предсказания d ;[п] будет равна


Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности s[n> ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рис. 4.14) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой (см. §4.8). Фильтр W(z) , учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рис.4.14, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
Существует несколько различных способов формирования функции возбуждения: многоимпульсное, регулярно-импульсное и векторное (кодовое) возбуждение [36]. Соответствующие алгоритмы представляют многоимпульсное (MLPC), регулярно-импульсное (RPE-LPC) и линейное предсказание с кодовым возбуждением (code excited linear prediction — CELP). MLPC использует функцию возбуждения, состоящую из множества нерегулярных импульсов, положение и амплитуда которых выбирается так, чтобы минимизировать ошибку восстановления. Алгоритм RPE-LPC является разновидностью MLPC, когда импульсы имеют регулярную расстановку. В этом случае оптимизируется амплитуда и относительное положение всей последовательности импульсов в пределах сегмента речи. CELP представляет способ, который основывается на векторном квантовании. В соответствии с этим способом из кодовой книги возбуждающих последовательностей выбирается квазислучайный вектор, который минимизирует квадрат ошибки восстановления. Кодовая книга используется как на этапе сжатия речевого сигнала, так и на этапе его восстановления. Для восстановления сегмента речевого сигнала необходимо знать номер соответствующего вектора воз-бужденияг в кодовой книге, параметры фильтров Ai,(z) и A(z), коэффициент усиления. Восстановление речевого сигнала по указанным параметрам выполняется в декодере только с помощью элементов, входящих в верхнюю часть схемы, изображенной на рис.4.14.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
2) CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефонной связи;
3) VCELP со скоростью передачи 7,95 Кбит/с (vector sum excited linear prediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
4) LD-CELP (low-delay CELP) одобрен стандартом МККТТ G.728. В данном стандарте достигается небольшая задержка примерно 0,625 мс (обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией Ai,(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP),
Сжатие аудиосигналов

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций.

Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰).

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого.

Папиллярные узоры пальцев рук — маркер спортивных способностей: дерматоглифические признаки формируются на 3-5 месяце беременности, не изменяются в течение жизни.
Источник

