- Кодирование с линейным прогнозированием — Linear predictive coding
- СОДЕРЖАНИЕ
- Обзор
- Ранняя история
- Представления коэффициентов LPC
- Приложения
- Кодирование с линейным предсказанием (LPC — Linear Predictive Coding). Рекомендации G.728, G.729, G.723
- Линейное предсказание с кодовым возбуждением — Code-excited linear prediction
- Содержание
- Введение
- CELP декодер
- Кодировщик CELP
- Взвешивание шума
Кодирование с линейным прогнозированием — Linear predictive coding
Кодирования с линейным предсказанием ( LPC ) представляет собой метод , используемый в основном в аудио обработки сигналов и речевой обработки для представления спектральной огибающей в виде цифрового сигнала из речи в сжатом виде, с использованием информации о виде линейной модели прогнозирования . Это один из самых мощных методов анализа речи и один из наиболее полезных методов кодирования речи хорошего качества с низкой скоростью передачи данных, обеспечивающий высокоточные оценки параметров речи. КЛП является наиболее широко используемым методом в кодировании речи и синтеза речи .
СОДЕРЖАНИЕ
Обзор
LPC исходит из предположения, что речевой сигнал генерируется зуммером на конце трубки (для озвученных звуков), со случайным добавлением шипящих и хлопающих звуков (для глухих звуков, таких как свистящие и взрывные звуки ). Несмотря на кажущуюся грубость, эта модель на самом деле является близким приближением к реальности производства речи. Голосовая щель (пространство между голосовыми складками) производит шум, который характеризуется своей интенсивностью ( громкость ) и частота ( основной тон). Голосовой тракт (горло и рот) образует трубку, которая характеризуется ее резонансов; эти резонансы дают начало формантам или расширенным частотным полосам в производимом звуке. Шипение и хлопки производятся языком, губами и горлом во время свистящих и взрывных звуков.
LPC анализирует речевой сигнал, оценивая форманты, удаляя их эффекты из речевого сигнала и оценивая интенсивность и частоту оставшегося шума. Процесс удаления формант называется обратной фильтрацией, а оставшийся сигнал после вычитания отфильтрованного смоделированного сигнала называется остатком.
Числа, которые описывают интенсивность и частоту гудения, формант и остаточного сигнала, могут быть сохранены или переданы в другое место. LPC синтезирует речевой сигнал, обращая процесс: используйте параметры гудка и остаток для создания исходного сигнала, используйте форманты для создания фильтра (который представляет трубку) и пропустите источник через фильтр, в результате чего получится речь.
Поскольку речевые сигналы меняются со временем, этот процесс выполняется на коротких фрагментах речевого сигнала, которые называются кадрами; обычно от 30 до 50 кадров в секунду дают разборчивую речь с хорошим сжатием.
Ранняя история
Линейное прогнозирование (оценка сигнала) восходит как минимум к 1940-м годам, когда Норберт Винер разработал математическую теорию для расчета лучших фильтров и предикторов для обнаружения сигналов, скрытых в шуме. Вскоре после того, как Клод Шеннон установил общую теорию кодирования, работа над предиктивным кодированием была проведена Ч. Чапином Катлером , Бернардом М. Оливером и Генри К. Харрисоном. Питер Элиас в 1955 году опубликовал две статьи о кодировании сигналов с предсказанием.
Линейные предикторы применялись к анализу речи независимо Фумитадой Итакурой из Университета Нагоя и Сюдзо Сайто из Nippon Telegraph and Telephone в 1966 году и в 1967 году Бишну С. Аталем , Манфредом Р. Шредером и Джоном Бургом. Итакура и Сайто описали статистический подход, основанный на оценке максимального правдоподобия ; Атал и Шредер описали подход адаптивного линейного предсказателя ; Бург изложил подход, основанный на принципе максимальной энтропии .
В 1969 году Итакура и Сайто представили метод, основанный на частичной корреляции (PARCOR), Глен Каллер предложил кодирование речи в реальном времени, а Бишну С. Атал представил речевой кодер LPC на Ежегодном собрании Акустического общества Америки . В 1971 году компания Philco-Ford продемонстрировала LPC в реальном времени с использованием 16-битного оборудования LPC ; было продано четыре единицы. Технология LPC была развита Бишну Аталом и Манфредом Шредером в 1970–1980-х годах. В 1978 году Атал и Вишванат и др. BBN разработала первый алгоритм LPC с переменной скоростью . В том же году Атал и Манфред Р. Шредер из Bell Labs предложили речевой кодек LPC, называемый адаптивным предсказательным кодированием , в котором использовался алгоритм психоакустического кодирования, использующий маскирующие свойства человеческого уха. Позже это стало основой для техники перцептивного кодирования , используемой форматом сжатия звука MP3 , введенным в 1993 году. Линейное предсказание с кодовым возбуждением (CELP) было разработано Шредером и Аталом в 1985 году.
LPC является основой для технологии передачи голоса по IP (VoIP). В 1972 году Боб Кан из ARPA вместе с Джимом Форги ( Lincoln Laboratory , LL) и Дэйвом Уолденом ( BBN Technologies ) начали первые разработки в области пакетной речи, которые в конечном итоге привели к технологии передачи голоса по IP. Согласно неофициальной истории Лаборатории Линкольна, в 1973 году Эд Хофстеттер реализовал первый LPC в реальном времени со скоростью 2400 бит / с. В 1974 году была осуществлена первая двусторонняя пакетная речевая связь LPC в реальном времени через ARPANET со скоростью 3500 бит / с между лабораторией Каллера-Харрисона и Линкольна. В 1976 году была проведена первая конференция LPC по ARPANET с использованием сетевого голосового протокола между Каллером-Харрисоном, ISI, SRI и LL со скоростью 3500 бит / с.
Представления коэффициентов LPC
LPC часто используется для передачи информации о спектральной огибающей, и поэтому он должен быть устойчивым к ошибкам передачи. Прямая передача коэффициентов фильтра ( определение коэффициентов см. В линейном прогнозировании ) нежелательна, поскольку они очень чувствительны к ошибкам. Другими словами, очень маленькая ошибка может исказить весь спектр или, что еще хуже, небольшая ошибка может сделать фильтр предсказания нестабильным.
Существуют более сложные представления, такие как логарифмические отношения площадей (LAR), разложение по парам спектральных линий (LSP) и коэффициенты отражения . Среди них особенно популярно разложение LSP, поскольку оно обеспечивает стабильность предсказателя, а спектральные ошибки являются локальными для малых отклонений коэффициентов.
Приложения
КЛП является наиболее широко используемым методом в кодировании речи и синтеза речи . Обычно он используется для анализа речи и ресинтеза. Телефонные компании используют его как форму сжатия голоса, например, в стандарте GSM . Он также используется для безопасной беспроводной связи, где голос должен быть оцифрован , зашифрован и отправлен по узкому голосовому каналу; ранний пример этого является правительство США Навахо я .
Синтез LPC может использоваться для создания вокодеров, в которых музыкальные инструменты используются в качестве сигнала возбуждения для изменяющегося во времени фильтра, оцениваемого по речи певца. Это довольно популярно в электронной музыке . Пол Лански сделал известное компьютерное музыкальное произведение без всякой путаницы, используя кодирование с линейным предсказанием. [1] LPC 10-го порядка использовался в популярной обучающей игрушке Speak & Spell 1980-х годов .
LPC предикторы используются в Сокращенно , MPEG-4 ALS , FLAC , ШЕЛКОВОМ аудиокодека и других без потерь аудио кодеков.
LPC уделяется некоторое внимание как инструменту для тонального анализа скрипок и других струнных музыкальных инструментов.
Источник
Кодирование с линейным предсказанием (LPC — Linear Predictive Coding). Рекомендации G.728, G.729, G.723
При кодировании с линейным предсказанием моделируются различные параметры человеческой речи, которые передаются вместо отсчетов или их разности, требующих значительно большей пропускной способности канала. Следует заметить, что буферы, необходимые для хранения потоков данных, увеличивают задержку кодирования.
Первые реализации LPC, такие как LPC-вокодер, были предназначены ля передачи данных на низких скоростях – 2,4 и 4,8 кбит/с. На скорости 2,4 кбит/с обеспечивался приемлемый уровень разборчивости речи, однако качество, естественность и узнаваемость речи недостаточны. Поскольку этот метод сильно зависит от точного воспроизведения человеческой речи, его реализации, такие как LPC-вокодер, не подходят для сигналов неречевого происхождения, например сигналов модема.
Широко используемый в настоящее время метод кодирования с линейным предсказанием работает с блоками отсчетов, для каждого из которых вычисляется и передается частота основного тона, его амплитуда и информация о типе возбуждающего воздействия.
Структура синтезатора речи с линейным предсказанием показана на рис. 2.5. Здесь управляющий вход или сигнал возбуждения смоделирован в виде последовательности импульсов на частоте основного тона (для вокализованной речи) или случайный шум (для невокализированной речи).
Комбинированные спектральные составляющие потока от голосовых связок, голосового тракта и звукообразования за счет губ могут быть представлены цифровым фильтром с изменяющимися параметрами и передаточной функцией
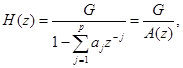 (2.7)
(2.7)
где 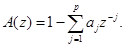
Параметрами, характеризующими голосовой тракт, являются коэффициенты знаменателя и масштабный множитель G.
Преобразуя уравнение (2.7) во временную область, можно получить разностное уравнение для импульсной характеристики 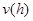 , соответствующей
, соответствующей 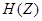 :
:
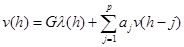 (2.8)
(2.8)
Уравнение (2.8) называют разностным уравнением LPC. Оно устанавливает, что текущее значение выходного сигнала может быть определено суммированием взвешенного текущего входного значения и взвешенной суммы предыдущих выходных выборок. Следовательно, в LPC анализе проблема может быть сформулирована так: даны измерения сигнала , требуется определить параметры передаточной функции системы 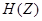 .
.
Линейное предсказание при анализе речевых сигналов обычно используется в двух направлениях. Одно из них – проведение кратковременного спектрального анализа речи. Второе направление – построение систем анализа-синтеза.
Параметры, входящие в функцию предсказания, через формулу (2.7) определяют параметры передаточной функции голосового тракта. Может быть предложено несколько вариантов структуры анализатора, пригодных для построения синтезатора и реализующих передаточную функцию голосового тракта. Структуру прямой формы можно получить непосредственно по коэффициентам функции предсказания. С другой стороны, дробь (2.7) можно преобразовать в произведение и получить структуру каскадной формы.
Во всех случаях параметры синтезатора непрерывно обновляются при смене анализируемых кадров речи. Чтобы избежать эффектов, связанных со скачками значений параметров, необходимо плавно изменять параметры с помощью интерполяции при переходе от одного участка речи к другому. При прямой форме синтеза может возникать ситуация, соответствующая неустойчивому фильтру, хотя исходные значения относились к устойчивому фильтру. В каскадной структуре устойчивость обеспечивается проще.Определение параметров возбуждающего сигнала в системе анализа-синтеза с линейным предсказанием, как правило, основывается на исследовании сигнала ошибки, получаемого пропусканием исходного речевого сигнала через фильтр с характеристикой, обратной той характеристике, которая аппроксимирует передаточную функцию голосового тракта. Полученный сигнал ошибки является аппроксимацией сигнала, возбуждающего речевое колебание. Для определения параметров возбуждающего сигнала можно применить один из известных алгоритмов различения звонкой и глухой речи, а также оценки периода основного тона, например на основе рассмотренного выше корреляционного анализа сигналов во временной области.
Источник
Линейное предсказание с кодовым возбуждением — Code-excited linear prediction
Линейное предсказание с кодовым возбуждением ( CELP ) — это алгоритм кодирования речи с линейным предсказанием , первоначально предложенный Манфредом Р. Шредером и Бишну С. Аталом в 1985 году. В то время он обеспечивал значительно лучшее качество, чем существующие алгоритмы с низкой скоростью передачи данных, такие как остаточные алгоритмы. -excited линейного предсказания (ОВЛП) и кодирования с линейным предсказанием (LPC) вокодеры (например, FS-1015 ). Наряду с его вариантами, такими как алгебраический CELP , ослабленный CELP , CELP с малой задержкой и линейное прогнозирование с векторной суммой , в настоящее время это наиболее широко используемый алгоритм кодирования речи. Он также используется в кодировании речи MPEG-4 Audio . CELP обычно используется как общий термин для класса алгоритмов, а не для конкретного кодека.
Содержание
Введение
Алгоритм CELP основан на четырех основных идеях:
- Использование модели источника-фильтра при формировании речи посредством линейного предсказания (LP) (см. Учебник «Алгоритм кодирования речи»);
- Использование адаптивной и фиксированной кодовой книги в качестве входа (возбуждения) модели LP;
- Выполнение поиска в замкнутом цикле в «перцептуально взвешенной области».
- Применение векторного квантования (VQ)
Исходный алгоритм, смоделированный в 1983 году Шредером и Аталом, требовал 150 секунд для кодирования 1 секунды речи при запуске на суперкомпьютере Cray-1 . С тех пор более эффективные способы реализации кодовых книг и улучшения вычислительных возможностей сделали возможным запуск алгоритма во встроенных устройствах, таких как мобильные телефоны.
CELP декодер

Прежде чем исследовать сложный процесс кодирования CELP, мы представим здесь декодер. На рисунке 1 показан общий декодер CELP. Возбуждение создается путем суммирования вкладов от фиксированной (также известной как стохастический или инновационный) и адаптивной (также известной как шаг) кодовых книг:
е [ п ] знак равно е ж [ п ] + е а [ п ] <\ Displaystyle е [п] = е_ <е>[п] + е_ <а>[п] \,> 
где является фиксированной (ака стохастические или инновации) вклад кодовой книги и является адаптивным ( шаг ) вклад кодовой книги. Фиксированная кодовая книга — это словарь векторного квантования, который (неявно или явно) жестко закодирован в кодеке. Эта кодовая книга может быть алгебраической ( ACELP ) или сохраняться явно (например, Speex ). Записи в адаптивной кодовой книге состоят из отложенных версий возбуждения. Это позволяет эффективно кодировать периодические сигналы, например звонкие звуки. е ж [ п ] <\ displaystyle e_ е а [ п ] <\ Displaystyle е_ <а>[п]>
Фильтр, формирующий возбуждение, имеет всеполюсную модель формы , которая называется фильтром прогнозирования и получается с использованием линейного прогнозирования ( алгоритм Левинсона – Дурбина ). Всеполюсный фильтр используется потому, что он хорошо отображает голосовой тракт человека и потому, что его легко вычислить. 1 / А ( z ) <\ displaystyle 1 / A (z)> А ( z ) <\ Displaystyle А (г)>
Кодировщик CELP
Основной принцип, лежащий в основе CELP, называется анализом путем синтеза (AbS) и означает, что кодирование (анализ) выполняется путем перцепционной оптимизации декодированного (синтезируемого) сигнала в замкнутом цикле. Теоретически лучший поток CELP можно получить, попробовав все возможные битовые комбинации и выбрав ту, которая дает декодированный сигнал с наилучшим звучанием. Очевидно, что на практике это невозможно по двум причинам: требуемая сложность выходит за рамки любого доступного в настоящее время оборудования, и критерий выбора «наилучшее звучание» предполагает наличие слушателя-человека.
Чтобы достичь кодирования в реальном времени с использованием ограниченных вычислительных ресурсов, поиск CELP разбивается на более мелкие, более управляемые, последовательные поиски с использованием простой функции перцепционного взвешивания. Обычно кодирование выполняется в следующем порядке:
- Коэффициенты линейного предсказания (LPC) вычисляются и квантуются, обычно как линейные спектральные пары (LSP).
- Выполняется поиск адаптивной кодовой книги (основного тона), и ее вклад удаляется.
- Выполняется поиск в фиксированной (инновационной) кодовой книге.
Взвешивание шума
Большинство (если не все) современных аудиокодеков пытаются сформировать шум кодирования так, чтобы он появлялся в основном в частотных областях, где ухо не может его обнаружить. Например, ухо более устойчиво к шуму в более громких частях спектра и наоборот. Вот почему вместо минимизации простой квадратичной ошибки CELP минимизирует ошибку для перцепционно взвешенной области. Весовой фильтр W (z) обычно получается из фильтра LPC с использованием расширения полосы пропускания :
W ( z ) знак равно А ( z / γ 1 ) А ( z / γ 2 ) <\ Displaystyle W (z) = <\ гидроразрыва )> )>>>
где . \gamma _<2>>»> γ 1 > γ 2 <\ displaystyle \ gamma _ <1>> \ gamma _ <2>> \ gamma _ <2>«>
Источник

