Архитектура x86
Архитектура x86 — Предсказание ветвлений
Содержание материала
Предварительное ( опережающее ) декодирование
и кэширование
В любой более — менее сложной программе присутствуют команды условного перехода : «Если некое условие истинно — перейти к исполнению одного участка кода , если нет — другого» . С точки зрения скорости выполнения кода программы современным процессором , поддерживающим внеочередное исполнение , любая команда условного перехода — воистину бич божий . Ведь до тех пор , пока не станет известно , какой участок кода после условного перехода окажется «актуальным» — его невозможно начать декодировать и исполнять ( см . внеочередное исполнение ). Для того чтобы как — то примирить концепцию внеочередного исполнения с командами условного перехода , предназначается специальный блок : блок предсказания ветвлений . Как понятно из его названия , занимается он , по сути , «пророчествами» : пытается предсказать , на какой участок кода укажет команда условного перехода , ещё до того , как она будет исполнена . В соответствии с указаниями «штатного внутриядерного пророка» , процессором производятся вполне реальные действия : «напророченный» участок кода загружается в кэш ( если он там отсутствует ), и даже начинается декодирование и выполнение его команд . Причём среди выполняемых команд также могут содержаться инструкции условного перехода , и их результаты тоже предсказываются , что порождает целую цепочку из пока не проверенных предсказаний ! Разумеется , если блок предсказания ветвлений ошибся , вся проделанная в соответствии с его предсказаниями работа просто аннулируется .
На самом деле , алгоритмы , по которым работает блок предсказания ветвлений , вовсе не являются шедеврами искусственного интеллекта . Преимущественно они просты . и тупы . Ибо чаще всего команда условного перехода встречается в циклах : некий счётчик принимает значение X, и после каждого прохождения цикла значение счётчика уменьшается на единицу . Соответственно , до тех пор , пока значение счётчика больше нуля — осуществляется переход на начало цикла , а после того , как он становится равным нулю — исполнение продолжается дальше . Блок предсказания ветвлений просто анализирует результат выполнения команды условного перехода , и считает , что если N раз подряд результатом стал переход на определённый адрес — то и в N+1 случае будет осуществлён переход туда же . Однако , несмотря на весь примитивизм , данная схема работает просто замечательно : например , в случае , если счётчик принимает значение 100, а «порог срабатывания» предсказателя ветвлений (N) равен двум переходам подряд на один и тот же адрес — легко заметить , что 97 переходов из 98 будут предсказаны правильно !
Разумеется , несмотря на достаточно высокую эффективность простых алгоритмов , механизмы предсказания ветвлений в современных CPU всё равно постоянно совершенствуются и усложняются — но тут уже речь идёт о борьбе за единицы процентов : например , за то , чтобы повысить эффективность работы блока предсказания ветвлений с 95 процентов до 97, или даже с 97% до 99.
Блок предвыборки данных (Prefetch) очень похож по принципу своего действия на блок предсказания ветвлений — с той только разницей , что в данном случае речь идёт не о коде , а о данных . Общий принцип действия такой же : если встроенная схема анализа доступа к данным в ОЗУ решает , что к некоему участку памяти , ещё не загруженному в кэш , скоро будет осуществлён доступ — она даёт команду на загрузку данного участка памяти в кэш ещё до того , как он понадобится исполняемой программе . «Умно» ( результативно ) работающий блок предвыборки позволяет существенно сократить время доступа к нужным данным , и , соответственно , повысить скорость исполнения программы . К слову : грамотный Prefetch очень хорошо компенсирует высокую латентность подсистемы памяти , подгружая нужные данные в кэш , и тем самым , нивелируя задержки при доступе к ним , если бы они находились не в кэше , а в основном ОЗУ .
Однако , разумеется , в случае ошибки блока предвыборки данных , неизбежны негативные последствия : загружая де — факто «ненужные» данные в кэш , Prefetch вытесняет из него другие ( быть может , как раз нужные ). Кроме того , за счёт «предвосхищения» операции считывания , создаётся дополнительная нагрузка на контроллер памяти ( де — факто , в случае ошибки — совершенно бесполезная ).
Алгоритмы Prefetch, как и алгоритмы блока предсказания ветвлений , тоже не блещут интеллектуальностью : как правило , данный блок стремится отследить , не считывается ли информация из памяти с определённым «шагом» ( по адресам ), и на основании этого анализа пытается предсказать , с какого адреса будут считываться данные в процессе дальнейшей работы программы . Впрочем , как и в случае с блоком предсказания ветвлений , простота алгоритма вовсе не означает низкую эффективность : в среднем , блок предвыборки данных чаще «попадает» , чем ошибается ( и это , как и в предыдущем случае , прежде всего связано с тем , что «массированное» чтение данных из памяти , как правило происходит в процессе исполнения различных циклов ).
Я — тот кролик , который не может начать жевать траву до тех пор , пока
не поймёт во всех деталях , как происходит процесс фотосинтеза !
( изложение личной позиции одним из близких знакомых автора )
Вполне возможно , те чувства , которые у вас возникли после прочтения данной статьи , можно описать примерно следующим образом : «Вместо того чтобы на пальцах объяснить , какой процессор лучше — взяли и загрузили мне мозги кучей специфической информации , в которой ещё разбираться и разбираться , и конца — края не видно ! » Вполне нормальная реакция : поверьте , мы вас хорошо понимаем . Скажем даже больше ( и пусть с головы упадёт корона !): если вы думаете , что мы сами можем ответить на этот простецкий вопрос ( «какой процессор лучше ? » ) — то вы очень сильно заблуждаетесь . Не можем . Для одних задач лучше один , для других — другой , а тут ещё цена разная , доступность , симпатии конкретного пользователя к определённым маркам . Не имеет задача однозначного решения . Если бы имела — наверняка кто — то бы его нашёл , и стал бы самым знаменитым обозревателем за всю историю независимых тестовых лабораторий .
Хотелось бы подчеркнуть ещё раз : даже полностью усвоив и осмыслив всю информацию , изложенную в данном материале — вы по — прежнему не сможете предсказать , какой из двух процессоров будет быстрее в ваших задачах , глядя только на их характеристики . Во — первых — потому , что далеко не все характеристики процессоров здесь рассмотрены . Во — вторых — потому , что есть и такие параметры CPU, которые в числовом виде могут быть представлены только с очень большой «натяжкой» . Так для кого же ( и для чего ) всё это написано ? В основном — для тех самых «кроликов» , которые непременно желают знать , что происходит внутри тех устройств , которыми они пользуются ежедневно . Зачем ? Может , они просто лучше себя чувствуют , когда знают , что вокруг них происходит ? 🙂
Добавить комментарий
Не использовать не нормативную лексику.
Просьба писать ваши замечания, наблюдения и все остальное,
что поможет улучшить предоставляемую информацию на этом сайте.
ВСЕ КОММЕНТАРИИ МОДЕРИРУЮТСЯ ВРУЧНУЮ, ТАК ЧТО СПАМИТЬ БЕСПОЛЕЗНО!
Источник
Блок предсказаний переходов и архитектура APM.
Встретив инструкцию перехода, процессор останавливает конвейер. Задержка будет тем дольше, чем больше длина конвейера.
Поэтому инструкции перехода надо выявлять заранее и реагировать соответствующим образом. Для этого предназначен специальный блок предсказания переходов. Его задача — предвидеть направление перехода и, в случае удачного предсказания, сэкономить время. Соответственно, если результат предсказания будет неудачным, происходит полная остановка конвейера и очистка буферов.
Если в программе есть условные переходы (то есть такие, которые зависят от результата выполнения какой-либо операции), надо постараться «угадать», произойдет этот переход, или нет. Поэтому блок предсказаний хранит специальную таблицу истории переходов, в которой записана результативность предыдущих примерно 4000 предсказаний. Кроме того, отслеживается точность последнего предсказания, чтобы при необходимости откорректировать алгоритм работы. Благодаря этому декодер выполняет по подсказке блока предсказания условный переход, а затем блок предсказаний проверяет, правильно ли было предсказано это условие.
Процент попаданий – 90-95%.
Архитектура ARM (Advanced RISC Machine, Acorn RISC Machine, усовершенствованная RISC-машина) — семейство лицензируемых 32-битных и 64-битных микропроцессорных ядер разработки компании ARM Limited
Процессоры ARM широко используются в потребительской электронике — в том числе КПК, мобильных телефонах, цифровых носителях и плеерах, портативных игровых консолях, калькуляторах и компьютерных периферийных устройствах, таких как жесткие диски или маршрутизаторы.
Эти процессоры имеют низкое энергопотребление, поэтому находят широкое применение во встраиваемых системах и доминируют на рынке мобильных устройств, для которых немаловажен данный фактор.
Дата добавления: 2015-08-27 ; просмотров: 123 | Нарушение авторских прав
Источник
Предсказание переходов
Более эффективными для снижения потерь от конфликтов по управлению являются методы предсказания переходов. Они призваны максимально ускорить определение адреса команды, выполняемой после команды перехода.
Так как преимущества конвейерной обработки проявляются при большом числе последовательно выполненных команд, перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики ядер всех современных процессоров уделяют большое внимание.
Среди основных достоинств практически каждого ядра нового процессора производители рекламируют «улучшенный блок предсказания переходов». Суть конкретных механизмов, обеспечивающих эти улучшения, как правило, не детализируется. Однако здесь все-таки можно выделить несколько основных подходов.
Существуют статические и динамические методы предсказания переходов. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается программой-компилятором по заложенным в ней алгоритмам. Также это может делать и сам программист по опыту выполнения аналогичных программ либо по результатам тестового выполнения программы.
Суть динамического метода предсказания заключается в том, что при выполнении команды условного перехода специальный блок процессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется. Предсказание направления переходов выполняется на основании результатов предыдущих выполнений данной команды.
Ядро процессора начинает выбирать из подсистемы памяти и выполнять команды по предсказанной ветви программы (так называемое выполнение по предположению, или «спекулятивное» выполнение). Однако так как направление перехода может быть предсказано неверно, получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап ЗР), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, и выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, все команды, выбранные после перехода, помечаются как недействительные.
При этом буфер результатов и конвейер, содержащий команды, которые следуют за командой условного перехода и находятся на разных этапах обработки, — очищаются. Аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы.
Следует отметить, что конфликты по управлению не исчерпываются только проблемами, связанными с командами условных переходов. Они возникают при выполнении всех команд, меняющих значение счетчика команд. Это хорошо видно из табл. 30.1. Если команда i является командой такого типа (например, команда безусловного перехода), то адрес перехода будет вычислен ею в такте 5, в то время как уже в такте 2 необходимо выбирать следующую команду по этому адресу.
Для команд безусловных переходов однажды вычисленный целевой адрес сохраняется в специальной памяти BTB (Branch Target Buffer), откуда он извлекается сразу же при дешифрации данной команды.
Аналогичный подход используется для команд вызова процедуры и — возврата из нее (анализ связок CALL — RETURN).
Источник
Предсказатель переходов
Из Википедии — свободной энциклопедии
Модуль предсказания переходов (прогнозирования ветвлений) (англ. branch prediction unit ) — устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, предсказывающее, будет ли выполнен условный переход в исполняемой программе. Предсказание ветвлений позволяет сократить время простоя конвейера за счёт предварительной загрузки и исполнения инструкций, которые должны выполниться после выполнения инструкции условного перехода. Прогнозирование ветвлений играет критическую роль, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора [1] .
Без предсказания переходов конвейер должен дождаться выполнения инструкции условного перехода, чтобы произвести следующую выборку. Предсказатель переходов позволяет избежать траты времени, пытаясь выяснить ответвление. Ответвление выбирается по предыдущим результатам проверки условия. Предполагаемое ответвление затем загружается и частично выполняется. Если затем обнаруживается, что предсказание было выполнено неверно, отменяются результаты неверного ветвления и в конвейер загружается правильное ответвление, производя задержку. Величина задержки зависит от длины конвейера. Для процессора Intel Core i7 глубина конвейера составляет 14 стадий.
Следует отличать «предсказание переходов» от «предсказания адреса перехода» [en] . Цель предсказания адреса перехода состоит в выборе адреса условного или безусловного перехода до декодирования и выполнения инструкции перехода.
Существует два основных метода предсказания переходов:
Источник
Предсказание переходов




![]()
![]()
Рассмотрим понятие модуля предсказания переходов — устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, предсказывающее, будет ли выполнен условный переходов исполняемой программе.
Для предсказания переходов процессор использует расширенный алгоритм Yeh’а, позволяющий с большой достоверностью спрогнозировать, будет ли выполняться переход. Если предсказание окажется верным, то исполнение продолжится с малой задержкой или совсем без задержки. Если же предположение ошибочно, то частично выполненные команды придется удалять из конвейера, а новые команды выбирать из области памяти с правильным адресом, декодировать и выполнять их. Это повлечет за собой существенное снижение производительности, напрямую зависящее от глубины конвейера — для архитектуры P6 в случае ошибочного предсказания перехода потери составят от 4 до 15 тактов.
Алгоритм предсказания ветвлений является динамическим двухуровневым и основывается на поведении команд перехода за предшествующий период, а также на поведении конкретных групп команд, для которых с большой вероятностью можно предсказать конкретный переход. Точность предсказания данного алгоритма составляет порядка 90 процентов.
Предположим, что ничего исключительного не происходит и что буфер переходов в своих предсказаниях оказался прав (в P6 предусмотрены эффективные действия в случае неправильного предсказания перехода).
Кэш команд выбирает строку кэша, соответствующую индексу в указателе на следующую команду, и следующую за ней строку, после чего передает 16 выровненных байтов декодеру. Две строки считываются из-за того, что команды в архитектуре Intel выровнены по границе байта, и поэтому может происходить передача управления на середину или конец строки кэша. Выполнение этой ступени конвейера занимает три такта, включая время, необходимое для вращения предвыбранных байтов и их подачи на декодеры команд. Начало и конец команд помечаются.
Три параллельных декодера принимают поток отмеченных байтов и обрабатывают их, отыскивая и декодируя содержащиеся в потоке команды. Декодер преобразует команды архитектуры Intel в микрокоманды-триады (два операнда, один результат). Большинство команд архитектуры Intel преобразуются в одну микрокоманду, некоторые требуют четырех микрокоманд, а сложные команды требуют обращения к микрокоду, представляющему из себя набор заранее составленных последовательностей микрокоманд. Некоторые команды, так называемые байт-префиксы, модифицируют следующую за ними команду, что также усложняет работу декодера. Микрокоманды ставятся в очередь, посылаются в таблицу псевдонимов регистров, где ссылки на логические регистры преобразуются в ссылки на физические регистры P6, после чего каждая из микрокоманд вместе с дополнительной информацией о ее состоянии (статусе) посылается в пул команд. Пул команд реализован в виде массива контекстно-адресуемой памяти, называемого также буфером переупорядочивания.
Пул команд – это буфер переупорядочения.
Прежде чем попасть в пул команд (известный формально, как буфер переупорядочения) поток микроинструкций имеет тот порядок, который определяется потоком команд процессора, посылаемым в дешифратор команд. Никакого переупорядочения команд нет.
Буфер переупорядочения представляет собой массив ассоциативной памяти, состоящей из 40 регистров микроинструкций. Он содержит микроинструкции, ожидающие исполнения, а также выполненные микроинструкции, результаты которых еще не зафиксированы в состоянии процессора. Блок диспетчирования/исполнения может выполнить микроинструкции из этого буфера в любом порядке.
Более подробно об алгоритме yeh-а.
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 52б
Принципы организации шин расширения. ISA, VLB, PCI как последовательные этапы перехода к централизации вычислительной системы относительно магистрали. Сопроцессоры, влияние сопроцессоров на принципы Фон-Неймана. Архитектура систем реального времени (СРВ). Базовые модули. Выполняемые функции.

Шины расширения предназначены для подключения различных адаптеров, периферийных устройств, расширяющих возможности компьютерной системы. Первая шина ISA была 8-битная. Улучшенная версия шины ISA – это EISA, появилась в связи с потребностью высокопроизводительном обмене для серверов. Начиная с процессора 486, было необходимо резко повысить производительность системной шины, и в результате появилась локальная шина VLB (использовалась для графических карт и дисковых контроллеров). С появлением 486 процессора появилась шина 88 PCI. Она явилась новым уровнем в архитектуре ПК, к которому подключились шины ISA и EISA. На сегодня это стандартная шина для процессоров 4, 5, 6 поколения, а также используется для таких платформ, как PowerPC и некоторые другие. Развитием шины PCI является порт AGP, предназначенный для подключения мощных графических адаптеров. Шины расширения системного уровня позволяют устанавливаемым модулям расширения максимально использовать системные ресурсы ПК: пространство памяти, ввода/вывода, системные прерывания, команды DMA. При этом необходимо обеспечить точное соответствие протоколам шины (включая жесткие частотные и нагрузочные параметры и временные диаграммы). Нарушение этих требований может заблокировать работу, как конкретного устройства, так и системы в целом.
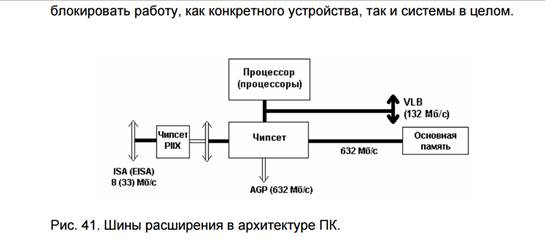
Шина ISA (Industry Standard Architecture)
Шина расширения ISA (Industry Standart Architecture) имеет два основных исполнения и несколько модификаций, которые в настоящее время уже канули в лету. Первый вариант – это оригинальная 8-разрядная шина расширения IBM PC, второй – 16-разрядный, появился в компьютерах IBM PC AT. Длительное время шина ISA была основным промышленным стандартом для подключения самой разнообразной периферии, когда не требуется особое быстродействие. Начиная со спецификации РС98, в разработке которой активное участие принимали корпорации Intel и Microsoft, производителям рекомендуется заменять шину ISA более современными типами.
Для 8-разрядной версии используется один 62-контактный щелевой разъем, в который вставляется плата расширения с контактами, выполненными непосредственно на печатной плате.
В усовершенствованной версии шины ISA используется 16-разрядная шина данных и 24-разрядные адреса. Конструктивно расширение было сделано за счет установки второго 36-контактного разъема, правда в дальнейшем оба разъема шины ISA объединили в один.
Кроме линий адреса и данных, на шине ISA имеются сигналы управления, с помощью которых производится запись/чтение данных и разрешение конфликтов между устройствами, вставленными в слоты ISA.
Платы расширения с восьмибитной шиной могут вставляться в 16-битный слот без каких-либо проблем.
Для увеличения производительности шины ISA одно время совместно с ней использовалась шина VLB (VESA [4] Local BUS). При этом питание и ряд сигналов управления плата расширения получала через шину ISA, а обмен данными происходил через шину VLB, которая непосредственно подключалась к системной шине процессора.
Шины PCI (Peripheral Component Interconnect ) local bus.
Шина для соединения периферийных компонентов. Является мостом между системной шиной процессора и шиной ввода/вывода ISA и EISA. Эта шина была разработана в расчете на Pentium системы, однако хорошо совместима и не с процессорами Intel. PCI является стандартизированной, высокопроизводительной шиной расширения ввода/вывода.
Шина PCI является независимой от других шин и позволяет осуществлять связь между любыми узлами.
Наиболее интересной особенностью шины PCI является принцип Bus Mastering, когда внешнее устройство без помощи центрального процессора может управлять шиной, становясь главным устройством при передаче данных. То есть в компьютере может одновременно (без временного разделения) выполняться, например, две задачи — процессор занимается одной задачей, а контроллер винчестера загружает данные в память через шину PCI.
Шины VLB (VESA Local Bus)
Появление локальной шины было первым шагом к формированию архитектуры ПК с несколькими шинами, имеющими разную пропускную способность. Локальная шина не заменяла собой ISA или EISA, а дополняла их за счет нескольких (не более трех) разъемов локальной шины. Первоначально эти шины использовались для обмена процессора с видеоадаптером, для которого уже не хватало скорости работы ISA.
Шина VL-bus позволяет таким периферийным устройствам, как видеоадаптеры и контроллеры накопителей, работать с тактовой частотой до 66 МГц. Она представляет собой двунаправленную 32-разрядную шину данных с теоретической пропускной способностью 160 Мбайт/с (при частоте шины 50 МГц) и 107 Мбайт/с при частоте 33 МГц.
В качестве устройств, подключаемых к VL-bus, выступают контроллеры накопителей, видеоадаптеры и сетевые платы. Конструктивно VL-bus представляет собой короткий разъем типа MCA (112 контактов), установленный позади разъемов расширения ISA или EISA. При этом 32 линии используются для передачи данных и 30 — для передачи адреса.
Принципы Фон — Неймана
1. Использование двоичной системы счисления в вычислительных машинах. Преимущество перед десятичной системой счисления заключается в том, что устройства можно делать достаточно простыми, арифметические и логические операции в двоичной системе счисления также выполняются достаточно просто.
2. Программное управление ЭВМ. Работа ЭВМ контролируется программой, состоящей из набора команд. Команды выполняются последовательно друг за другом.
3. Память компьютера используется не только для хранения данных, но и программ. При этом и команды программы и данные кодируются в двоичной системе счисления, т.е. их способ записи одинаков. Поэтому в определенных ситуациях над командами можно выполнять те же действия, что и над данными.
4. Ячейки памяти ЭВМ имеют адреса, которые последовательно пронумерованы. В любой момент можно обратиться к любой ячейке памяти по ее адресу. Этот принцип открыл возможность использовать переменные в программировании.
5. Возможность условного перехода в процессе выполнения программы. Не смотря на то, что команды выполняются последовательно, в программах можно реализовать возможность перехода к любому участку кода.
Самым главным следствием этих принципов можно назвать то, что теперь программа уже не была постоянной частью машины (как например, у калькулятора). Программу стало возможно легко изменить. А вот аппаратура, конечно же, остается неизменной, и очень простой.
СОПРОЦЕССОР. В тех случаях, когда на компьютере приходится выполнять много математических вычислений (например, в инженерных расчетах), к основному микропроцессору добавляют математический сопроцессор. Он помогает основному микропроцессору выполнять математические операции над вещественными числами. Новейшие микропроцессоры фирмы Intel (80486 и Pentium) сами умеют выполнять операции над вещественными числами, так что для них сопроцессоры не требуются.
Источник

